Data & Analytics > DataQuery > コンソール使用ガイド
DataQueryサービスを使用するには、必ずデータソースを追加する必要があります。 以下のような手順でサービスを使用できます。
- 連動するデータソース追加
- データソースを反映するためのクラスタ起動
- Webコンソールのクエリエディタまたは外部接続URLを介した別途ツールでのクエリ実行
データソース
データソース追加
- データソース設定および反映制約事項
- Object Storageタイプのデータソースが存在している時のみ他のデータソースを追加できます。
- Object Storageタイプのデータソースが存在する時のみクラスタを有効にしてクエリを実行できます。
- Object Storageタイプのデータソースは1つだけ登録できます。
- アクセス制御が設定されたデータソースに接続する場合は、DataQuery IP固定機能を使用する必要があります。
- DataQuery IP固定機能を使用する場合は、サポートにお問い合わせください。
- データソースの追加をクリックします。
Object Storageデータソースタイプ
- データソースの追加をクリックした後、データソースの追加ページでObject Storage情報を入力します。
- データソース名
- クエリ実行時に使用されるセパレータで、データソース間で一意の値なければなりません。
- アクセスキー、秘密鍵、リージョン
- 連動するデータが存在するObject Storageの接続情報です。
- アクセスキーと秘密鍵はObject Storageコンソールで発行できます。詳細についてはObject Storageコンソール使用ガイドをご覧ください。
- リージョンはObject Storageガイドのリージョン別S3リージョンをご覧ください。
- バケット名
- システムで基本テーブル情報や管理テーブル情報、データを保存するために使用するObject Storageコンテナ名(dataquery-warehouse)です。
- 独自にdataquery-warehouseコンテナを作成して使用します。
- 連動する既存データは、dataquery-warehouseコンテナ外部に存在できます。
- システムで基本テーブル情報や管理テーブル情報、データを保存するために使用するObject Storageコンテナ名(dataquery-warehouse)です。
- データソース名
- その他の事項
- 連動するObject Storageは、同じNHN Cloudプロジェクト外部に存在できます。
[注意] DataQueryと連動するObject Storageが同じリージョンではない場合、ネットワークトラフィックによる追加料金が発生する可能性があります。
- 連動するObject Storageは、同じNHN Cloudプロジェクト外部に存在できます。
MySQLデータソースタイプ
- データソース名 * クエリ実行時に使用されるセパレータで、データソース間で一意の値でなければなりません。
- 接続URL
- MySQLデータベース接続アドレスです。
- jdbc:mysql://[ホスト、ip]:[ポート]?[パラメータ]フォーマットで入力する必要があります。
- タイムゾーン処理が必要な場合、serverTimezoneパラメータを設定する必要があります。
- ex) jdbc:mysql://localhost:10000?serverTimezone=Asia/Seoul
- ユーザーID
- 接続するMySQLアカウント名です。
- パスワード
- 接続するMySQLパスワードです。
PostgreSQLデータソースタイプ
- データソース名
- クエリ実行時に使用される識別子で、データソース間で固有の値でなければなりません。
- 接続URL
- PostgreSQLデータベース接続アドレスです。
- jdbc:postgresql://[ホスト、ip]:[ポート]/[データベース]?[パラメータ]フォーマットで入力する必要があります。
- ユーザーID
- 接続するPostgreSQLアカウント名です。
- パスワード
- 接続するPostgreSQLパスワードです。
Oracleデータソースタイプ
- データソース名
- クエリ実行時に使用される識別子で、データソース間で固有の値でなければなりません。
- 接続URL
- Oracleデータベース接続アドレスです。
- jdbc:oracle:thin:@[ホスト、ip]:[ポート]:[SID] または jdbc:oracle:thin:@[ホスト、ip]:[ポート]/[SERVICE NAME] フォーマットで入力する必要があります。
- ユーザーID
- 接続するOracleアカウント名です。
- パスワード
- 接続するOracleパスワードです。
- 追加設定情報
- 未サポートタイプ処理:サポートしない列データタイプに対する処理方法を設定できます。
- 基本小数点以下の桁数: 全体の有効桁数(precision)、小数点以下の桁数(scale)設定がない数字の基本小数点桁数を設定します。
- 数字の切り上げ/切り捨て:Oracle NUMBERデータ型に対する切り上げ/切り捨てポリシーを設定します。
EDBデータソースタイプ
- データソース名
- クエリ実行時に使用される識別子で、データソース間で固有の値でなければなりません。
- 接続URL
- EDBデータベース接続アドレスです。
- jdbc:postgresql://[ホスト、ip]:[ポート]?[パラメータ] フォーマットで入力する必要があります。
- ユーザーID
- 接続するEDBアカウント名です。
- パスワード
- 接続するEDBパスワードです。
クエリエディタ
- クエリエディタはクラスタ領域、スキーマ領域、保存されたクエリ領域、エディタ領域、結果/コンソール実行領域に区分されます。
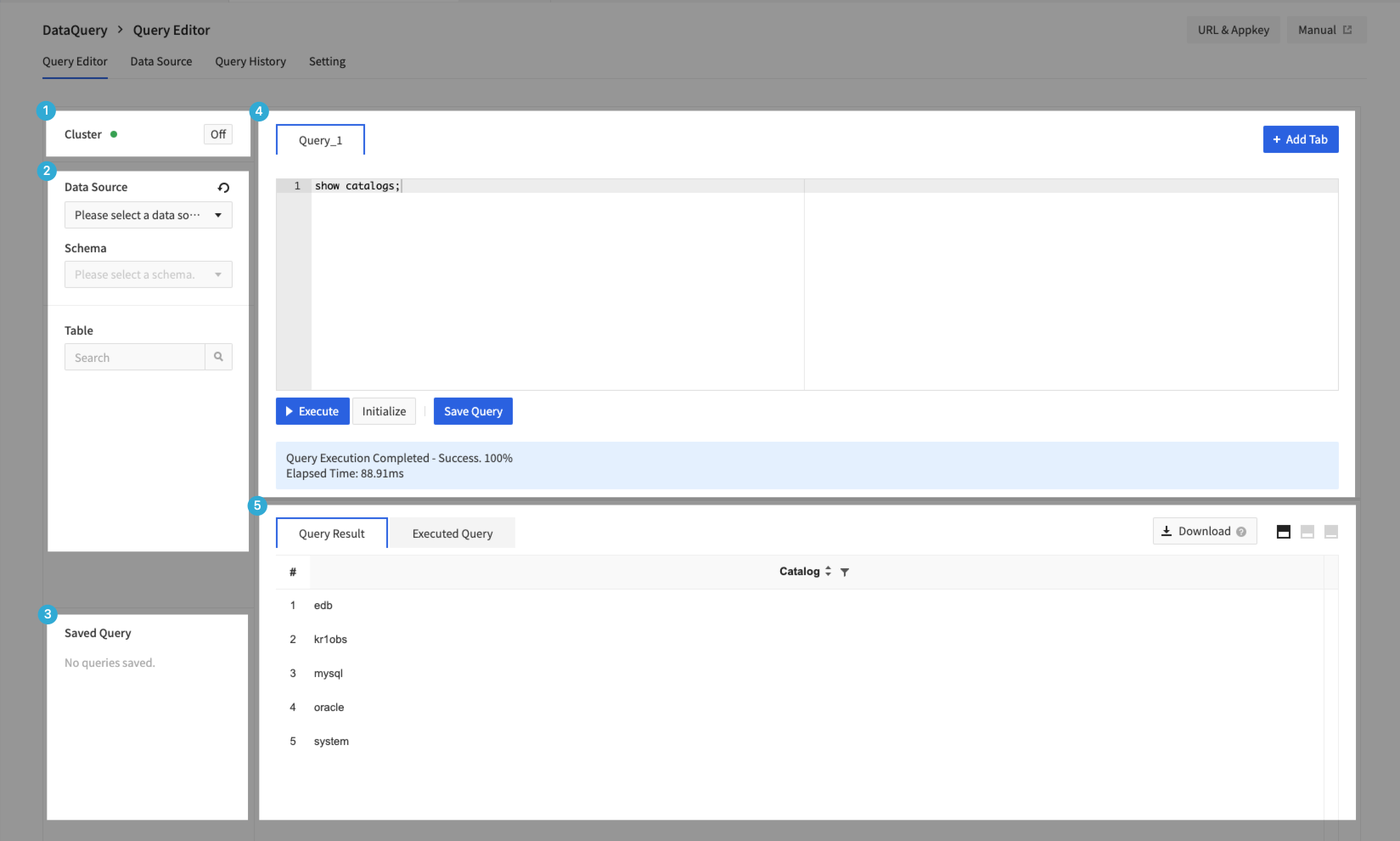
1. クラスタ領域
- クラスタのオン/オフを切り替えることができます。
- 追加、変更、削除したデータソース情報を実際の動作に反映させるにはDataQueryクラスタを再起動する必要があります。
- データソースの追加または変更、削除などの動作があった場合、以下のようにクラスタ再起動文言が表示されます。
- Object Storageは必須データソースであり、Object Storageデータソースが削除されるとクラスタの起動ができません。
- クラスタの電源を切るのに1~2分、電源を入れるのに3~4分程度の時間がかかることがあります。
- DataQueryクラスタはすべてのデータソースを反映し、個別のデータソース適用はできません。
- 継続的にクラスタのオン/オフに失敗する場合は、サポートにお問い合わせください。
2. スキーマ領域
- 接続設定されたデータソースと、該当ソースで提供する実際のDB 、テーブル、カラム情報を確認できます。
- information_schemaはデータソースとの接続情報を持っているDBで、ユーザーが任意にデータを操作できません。
- 各項目の更新アイコンをクリックして、データソース、スキーマ、テーブル、カラム情報を新しく取得できます。
- ただし、上位スキーマを更新しても下位情報は全部新しく読み込みません。テーブルを更新する場合、テーブルリストのみ新たに取得し、各テーブルのカラム情報はアップデートされません。
3. 保存されたクエリ領域
- ユーザーが保存したクエリを管理できます。
- 開くをクリックすると、現在開いているクエリエディタ領域に保存したクエリを呼び出すことができます。
- 新しいタブを開くをクリックすると、新しいクエリエディタ領域に保存されたクエリを呼び出すことができます。
- クエリのコピーをクリックすると、クリップボードに保存されたクエリをコピーできます。
4. エディタ領域
- + クエリ追加をクリックしてクエリエディタを最大10個まで作成できます。
- 実行をクリックするか、ctrl + enterを入力してクエリを実行でき、エディタ下部で実行中のクエリの進行状態と失敗時の原因ログを確認できます。
- クエリの保存をクリックすると、ユーザーがよく使うクエリを保存できます。
- クエリ作成時に収集されたデータソース、スキーマ、テーブル、カラム名のオートコンプリートをサポートします。
SQLガイド
- DataQueryのSQLはTrino基準に従って動作します。
- Trinoは標準SQL文法(ANSI SQL)に従います。
- Trinoは、独自にデータを持たず、複数のデータソースとの連動によりデータを処理します。
- データソースごとに例外的な文法や制約事項が存在する場合があります。
- トランザクション処理(OLTP)作業ではなく、分析処理(OLAP)作業に合わせて設計されました。
- データ型
- BOOLEAN、整数型、小数点、文字列、日付、UUID、ハイパーログなどのタイプをサポートします。
- Trinoクエリ
- DDL(Data Definition Language、データ定義語)、DML(Data Manipulation Language、データ操作語)をサポートし、以下の追加構文をサポートします。
- メタデータを確認できる構文:SHOW CATALOGS、SHOW SCHEMAS、SHOW TABLES、SHOW STATS FOR
- システムの内蔵プロシージャ(Procedure)を確認したりクエリの実行計画を確認したりできる構文:CALL、EXPLAIN
- DDL(Data Definition Language、データ定義語)、DML(Data Manipulation Language、データ操作語)をサポートし、以下の追加構文をサポートします。
- 詳細については、Trinoのガイド文書をご覧ください。
5. 結果/コンソール実行クエリ領域
- クエリエディタで実行されたクエリ結果を確認できます。
- データサイズに応じて約1MBまたは約5,000個程度の制限された結果を提供します。
- クエリ結果は最大30MBまでダウンロードできます。
- Trinoを直接連動(ex. JDBC、CLI)すると、クエリ実行結果全体のデータを取得できます。設定メニューガイドをご覧ください。
- クエリ結果はクエリ完了時刻から最大7日までダウンロードできます。12月1日13時53分32秒にクエリ実行が完了した場合、12月8日13時53分32秒の前までダウンロードできます。
- マウス右クリックしてコンソールクエリ結果のコピー、エクスポートを実行できます。
- クエリエディタで実行したクエリリストを提供します。
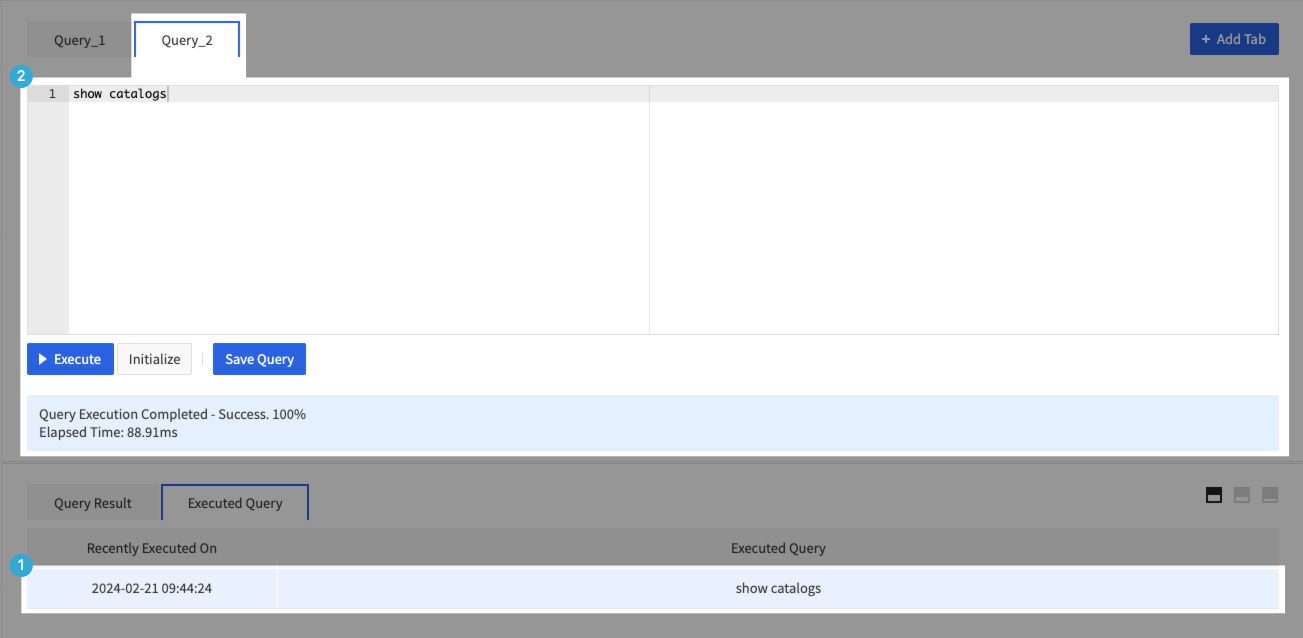
- ①クエリ履歴をクリックします。
- ②該当クエリが入力されたクエリウィンドウが追加作成されます。
クエリ履歴
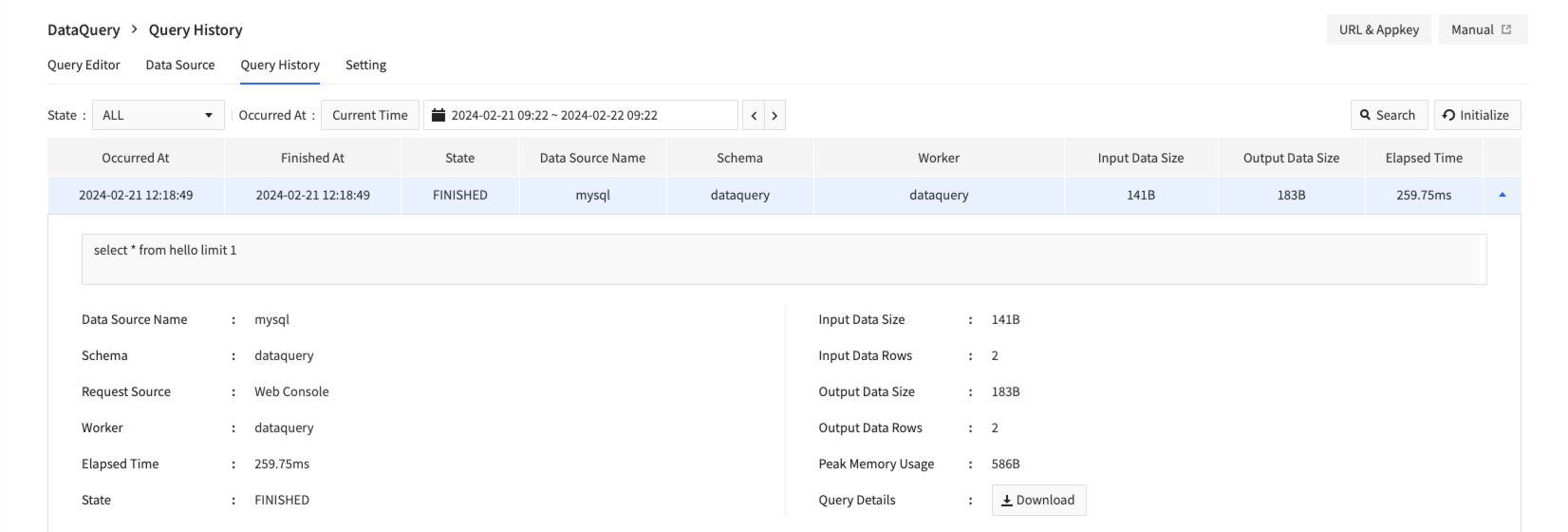
- 実行したクエリ情報をクエリ履歴画面で確認できます。
- 一番右の列の展開ボタンをクリックしてクエリの追加の実行情報を確認できます。ダウンロードをクリックしてクエリの全体実行情報をダウンロードできます。
- ダウンロードファイルにクエリ結果は含まれません。
設定
クラスタ設定
- クラスタに設定されているインスタンスタイプとノード数を確認できます。
- タイプについての説明や設定で提供されるリスト以外のタイプは、サービス別料金で確認できます。
- インスタンスタイプとワーカー 数を変更できます。
- ワーカー数は最小1個から最大5個まで設定できます。
- 設定はクラスターがオフの状態(OFF)でのみ修正できます。
外部連動
- 外部ツール(JDBC、CLI、BIソリューションなど)と連動できるようにTrinoエンドポイントを提供し、設定ページで提供する情報を利用して連動できます。
- エンドポイント接続には、個人別の認証情報が必要で、設定メニューで認証キー発行をクリックして発行できます。
- 個人別の認証情報は、IDと認証キーで構成されており、エンドポイントに接続する時、ユーザー名(ID)とパスワード(認証キー)として活用されます。
- パスワード(認証キー)は、最初の発行時にのみ確認できます。認証キーを紛失した場合は認証キーの再発行をクリックして新しい認証キーを発行する必要があります。
- 発行/再発行された認証キーは発行してから5分後に使用できます。
- 認証情報が発行された場合はTrinoエンドポイント接続情報が画面下部に有効になります。
データソース詳細ガイド
Object Storageデータソースクエリ実行
- Object Storageデータソースに対するクエリは、Trino-Hiveに基づいて実行されます。
- HiveはApache Hadoop分散ストレージ環境でSQL作業処理をサポートするためのソリューションです。
- DataQueryではObject StorageアクセスのためにS3互換レイヤーを使用し、スキーマまたはテーブルのためのデータパス指定時、s3aプロトコルを使用する必要があります(ex. s3a://example/test).
- Object Storage上のParquet、JSON、ORC、CSV、Textタイプのデータに対する処理をサポートします。
- Object Storageデータソースはdefaultという名前の基本スキーマを提供し、そのスキーマで作業できます。
Hive機能動作のための追加の文法
- Trino-Hiveは基本的に標準SQL文法に従いますが、Hive動作対応のための追加機能/文法が存在します。 詳細情報
- サポートデータフォーマット
- 基本フォーマットはORCに指定されており、設定でParquet、JSON、ORC、CSV、Textなどを指定できます。
- テーブル作成時、with節のformat値で指定できます。
CREATE TABLE sample (...) WITH ( format = 'タイプ')
- テーブルの種類
- 内部テーブル(Managed Table)
- DB作成時に指定された特定パスで(dataquery-warehouseバケット)テーブルデータが管理されます。
- テーブルを削除するとテーブル情報およびObject Storageに保存されたファイルも一緒に削除されます。
- テーブルを作成する時、別のオプションを指定しない場合、内部テーブルとして作成されます。
- 外部テーブル(External Table)
- ユーザーが指定した別のパスにあるデータに基づいて動作します。
- テーブルを削除すると、内部テーブルとは異なり接続されたデータ原本は削除されません。
- テーブルを作成する時、WITH節のexternal_locationにデータのパスを指定する必要があります。
- external_locationデータのパス入力時、バケット(コンテナ)名はNHN Cloud Object Storageのバケット命名ルールを守る必要があります。
- 内部テーブル(Managed Table)
# Managed Tableサンプル
CREATE TABLE sample (...);
# External Tableサンプル
CREATE TABLE sample (...) WITH ( external_location = 's3a://<バケット、コンテナ名>/<データディレクトリパス>/');
- パーティション(Partition)
- Hiveはデータを特定基準のディレクトリに分離して保存できるパーティション機能を提供します。
- テーブルにパーティションを適用したりパーティションを操作したりするには、次のようなクエリが必要です。
#テーブルにパーティションを適用して作成
CREATE TABLE default.sample (...) WITH ( partitioned_by = ARRAY['columna', 'columnb'],)
#パーティション照会
SELECT * FROM default"sample$partitions"
#パーティションを操作
system.create_empty_partition(schema_name, table_name, partition_columns, partition_values)
system.sync_partition_metadata(schema_name, table_name, mode, case_sensitive)
- 制約事項
- CSVタイプのテーブルカラムはVARCHARタイプのみサポートされます。
- DataQueryではObject StorageアクセスのためにS3互換レイヤーを使用し、スキーマまたはテーブルのためのデータパス指定時、s3aプロトコルを使用する必要があります(ex. s3a://example/test)。
- External tableのexternal_locationに指定されるデータディレクトリパスオブジェクトが別途存在する必要があります。
- Object Storageでディレクトリを別途作成した状態で、データが当該ディレクトリにある時のみ正常に連動します。
- 処理に問題がある場合は、サポートにお問い合わせください。
- External tableのexternal_locationパス名にハングルが入っている場合は正常にデータが処理されません。
- テーブルに接続されたObject Storageバケットが削除されるとテーブルDROPクエリが失敗します。
- DELETE、UPDATEはパーティションデータに対してのみ制限的に実行できます。
外部テーブルクエリ利用チュートリアル
- サンプルCSVファイルをダウンロードしてObject Storageにアップロードします。
- Object Storageコンソールでアクセスキー、シークレットキーを発行します。
- Object Storageのアクセスキー、シークレットキー、エンドポイントを利用してObject Storageデータソースを入力します。
- クエリエディタに移動し、先ほど追加したObject Storageデータソースを選択し、defaultスキーマを選択します。
- 次のようにCREATE TABLEクエリを入力して実行します。
CREATE TABLE corona_facility_us
(
facility_place_id varchar,
facility_provider_id varchar,
facility_name varchar,
facility_latitude varchar,
facility_longitude varchar,
facility_country_region varchar,
facility_country_region_code varchar,
facility_sub_region_1 varchar,
facility_sub_region_1_code varchar,
facility_sub_region_2 varchar,
facility_sub_region_2_code varchar,
facility_region_place_id varchar,
mode_of_transportation varchar,
travel_time_threshold_minutes varchar,
facility_catchment_boundary varchar
)
with (
format = 'csv',
external_location = 's3a://csv-test/corona-facility/'
)
- テーブルが正常に追加されたことを確認するためにテーブルを更新します。
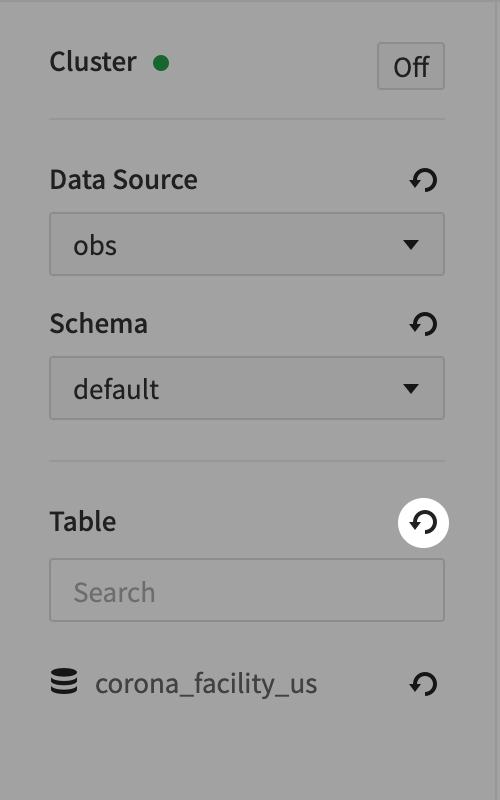
- 該当テーブルで、次のようにクエリを実行します。
SELECT * FROM corona_facility_us
WHERE facility_place_id = 'ChIJkxHDPsnTQIYR7MH7N-eIdQ0'
AND facility_latitude = '29.952'
- 合計10件のデータが正常に表示されていることを確認します。
MySQLデータソースクエリ実行
- MySQLデータソースに対するクエリはTrino-MySQLに基づいて行われます。
- MySQLデータソースのスキーマとテーブルは、小文字名に基づいて動作し、表現されます。
- 同じ名前で大文字/小文字が異なるテーブルがある場合、クエリ実行とスキーマ収集が正常に動作しない場合があります。
- 制約事項
- DELETEは特定の条件が満たされた場合のみ制限的に実行できます。
- where句が存在する時、術語(Predicate)がデータソースに完全にプッシュダウン(Pushdown)できる必要があります。
- テキストタイプの列はプッシュダウンがサポートされません。
- 詳細情報
- UPDATEは、特定の条件が満たされる場合のみ制限的に実行できます。
- 定数値への割り当てと術語(Predicate)が存在する場合のみ実行することができます。
- 算術式、関数呼び出しおよび定数以外の値へのUPDATE文はサポートされません。
- 条件節をANDで構成することはできません。
- テーブルのすべての列を同時に更新することはできません。
- 詳細情報
- DELETEは特定の条件が満たされた場合のみ制限的に実行できます。
PostgreSQLデータソースクエリの実行
- PostgreSQLデータソースに対するクエリは、Trino-PostgreSQLに基づいて実行されます。
- PostgreSQLデータソースのスキーマとテーブルは小文字の名前に基づいて動作し、表現されます。
- 大文字と小文字が異なる同じ名前のテーブルがある場合、クエリの実行とスキーマの収集が正常に動作しない場合があります。
- 制約事項
- DELETEは特定の条件が満たされた場合のみ制限的に実行できます。
- where句が存在する時、術語(Predicate)がデータソースに完全にプッシュダウン(Pushdown)できる必要があります。
- CHAR または VARCHAR のような文字列タイプに対する範囲条件(>, < または BETWEEN)はプッシュダウンがサポートされません。
- テキストタイプに対する等価比較条件(IN, =, !=)はプッシュダウンがサポートされます。
- 詳細情報
- UPDATEは、特定の条件が満たされる場合のみ制限的に実行できます。
- 定数値への割り当てと術語(Predicate)が存在する場合のみ実行することができます。
- 算術式、関数呼び出しおよび定数以外の値へのUPDATE文はサポートされません。
- 条件節をANDで構成することはできません。
- テーブルのすべての列を同時に更新することはできません。
- 詳細情報
- DELETEは特定の条件が満たされた場合のみ制限的に実行できます。
Oracleデータソースクエリの実行
- Oracleデータソースに対するクエリは、Trino-Oracleに基づいて実行されます。
- Oracleデータソースのスキーマとテーブルは、小文字の名前に基づいて動作し、表現されます。
- 大文字と小文字が異なる同じ名前のテーブルがある場合、クエリの実行とスキーマの収集が正常に動作しない場合があります。
- 制約事項
- DELETE, UPDATEは特定の条件が満たされる場合のみ制限的に実行できます。
- where句が存在する時、術語(Predicate)がデータソースに完全にプッシュダウン(Pushdown)できる必要があります。
- CLOB, NCLOB, BLOB, or RAW(n)であるOracleタイプの列はプッシュダウンがサポートされません。
- 詳細情報
- UPDATEは、特定の条件が満たされる場合のみ制限的に実行できます。
- 定数値への割り当てと術語(Predicate)が存在する場合のみ実行することができます。
- 算術式、関数呼び出しおよび定数以外の値へのUPDATE文はサポートされません。
- 条件節をANDで構成することはできません。
- テーブルのすべての列を同時に更新することはできません。
- 詳細情報
- DELETE, UPDATEは特定の条件が満たされる場合のみ制限的に実行できます。
EDBデータソースクエリの実行
- EDBデータソースに対するクエリは、Trino-PostgreSQLに基づいて実行されます。
- EDBデータソースのスキーマとテーブルは小文字の名前に基づいて動作し、表現されます。
- 大文字と小文字が異なる同じ名前のテーブルがある場合、クエリの実行とスキーマの収集が正常に動作しない場合があります。
- 制約事項
- DELETEは特定の条件が満たされた場合のみ制限的に実行できます。
- where句が存在する時、術語(Predicate)がデータソースに完全にプッシュダウン(Pushdown)できる必要があります。
- CHAR または VARCHAR のような文字列タイプに対する範囲条件(>, < または BETWEEN)はプッシュダウンがサポートされません。
- テキストタイプに対する等価比較条件(IN, =, !=)はプッシュダウンがサポートされます。
- 詳細情報
- UPDATEは、特定の条件が満たされる場合のみ制限的に実行できます。
- 定数値への割り当てと術語(Predicate)が存在する場合のみ実行することができます。
- 算術式、関数呼び出しおよび定数以外の値へのUPDATE文はサポートされません。
- 条件節をANDで構成することはできません。
- テーブルのすべての列を同時に更新することはできません。
- 詳細情報
- DELETEは特定の条件が満たされた場合のみ制限的に実行できます。
外部連動
Trino cli
- 設定メニューから発行された認証情報、接続情報、TrinoでサポートするCLIツールを利用してコマンドラインからクエリを実行できます。
- TrinoでサポートするCLIツールは最新バージョンを使用してください。
- 現在DataQueryで提供しているTrinoのバージョンは434です。
- Trino CLI
# ファイルに実行権限が必要です。chmod +xで付与できます。
# ex) chmod +x trino-cli-434-executable.jar
./trino-cli-434-executable.jar --server <接続URL(必須)> \
--user <ID(必須)> --password \
--catalog <データソース名> \
--schema <スキーマ名>
- 設定パラメータ
- 接続URL(必須)
- 設定画面で提供された接続URL (ex. https://x-x-x-x-x.kr1-cluster-dataquery.nhncloudservice.com)
- ID(必須)
- 認証情報画面で提供されたID
- パスワード(必須)
- 認証情報画面で提供されたパスワード
- コマンドを実行すると表示されるプロンプトウィンドウで入力するか、
export TRINO_PASSWORD=<パスワード>にあらかじめパスワードを設定しておくことができます。
- データソース名
- 接続したデータソース名
- スキーマ名
- 接続したデータベース名
- 接続URL(必須)
--debugオプションを追加してデバッグ情報を追加で出力できます。- catalog、schema値はコマンドを実行する接続に対する値で、入力しなくてもcli実行することができ、以下のクエリを利用してcatalogやschemaリストを確認できます。
- show catalogs
- show schemas
- 詳細はTrinoガイドページをご覧ください。
JDBC接続
- 設定メニューで発行された認証情報、接続情報と、TrinoでサポートするJDBCドライバーを利用してJDBCに接続できます。
jdbc:trino://${host}:${port}
jdbc:trino://${host}:${port}/${catalog}
jdbc:trino://${host}:${port}/${catalog}/${schema}
- 設定パラメータ
- host(必須)
- 設定画面で提供された接続URLで
https://以外の部分を入力します(ex . x-x-x-x-x.kr1-cluster-dataquery.nhncloudservice.com)。
- 設定画面で提供された接続URLで
- port(必須)
- 443を入力します。
- catalog
- 接続したいデータソース名
- schema
- 接続したいスキーマ名
- host(必須)
- 接続情報例
- jdbc:trino://test-dataquery-domain-12345abcd.kr1-cluster-dataquery.nhncloudservice.com:443/catalog/schema
- 詳細はTrino JDBCガイドページをご覧ください。
目次
- Data & Analytics > DataQuery > コンソール使用ガイド
- データソース
- データソース追加
- Object Storageデータソースタイプ
- MySQLデータソースタイプ
- PostgreSQLデータソースタイプ
- Oracleデータソースタイプ
- EDBデータソースタイプ
- クエリエディタ
- 1. クラスタ領域
- 2. スキーマ領域
- 3. 保存されたクエリ領域
- 4. エディタ領域
- 5. 結果/コンソール実行クエリ領域
- クエリ履歴
- 設定
- クラスタ設定
- 外部連動
- データソース詳細ガイド
- Object Storageデータソースクエリ実行
- MySQLデータソースクエリ実行
- PostgreSQLデータソースクエリの実行
- Oracleデータソースクエリの実行
- EDBデータソースクエリの実行
- 外部連動
- Trino cli
- JDBC接続