Machine Learning > AI EasyMaker > 콘솔 사용 가이드
대시보드
대시보드에서 전체 AI EasyMaker 리소스의 이용 현황을 확인할 수 있습니다.
서비스 이용 현황
리소스별로 이용 중인 리소스 수를 표시합니다.
- 노트북: 이용 중인 ACITVE(HEALTHY) 상태의 노트북 수
- 학습: 완료(COMPLETE)된 학습 수
- 하이퍼파라미터 튜닝: 완료(COMPLETE)된 하이퍼파라미터 튜닝 수
- 엔드포인트: ACTIVE 상태의 엔드포인트 수
서비스 모니터링
- API 호출이 가장 많은 Top 3 엔드포인트를 표시합니다.
- 엔드포인트를 선택하면 하위 엔드포인트 스테이지의 API 성공/실패 합계 지표를 확인할 수 있습니다.
리소스 사용률
- CPU, GPU 코어 타입별로 가장 사용량이 많은 리소스를 확인할 수 있습니다.
- 지표에 마우스 포인터를 올리면 리소스 정보가 표시됩니다.
노트북
머신 러닝 개발을 위한 필수 패키지가 설치되어 있는 주피터(Jupyter) 노트북을 생성하고 관리합니다.
노트북 생성
주피터 노트북을 생성합니다.
-
이미지: 노트북 인스턴스에 설치될 OS 이미지를 선택합니다.
- 코어 타입: 이미지의 CPU, GPU 코어 타입이 표시됩니다.
- 프레임워크: 이미지에 설치된 프레임워크가 표시됩니다.
- TENSORFLOW: TensorFlow 딥러닝 프레임워크가 설치된 이미지입니다.
- PYTORCH: PyTorch 딥러닝 프레임워크가 설치된 이미지입니다.
- PYTHON: 딥러닝 프레임워크가 설치되지 않고 파이썬 언어만 설치된 이미지입니다.
- 프레임워크 버전: 이미지에 설치된 프레임워크의 버전이 표시됩니다.
- 파이썬 버전: 이미지에 설치된 파이썬 버전이 표시됩니다.
-
노트북 정보
- 노트북의 이름, 설명을 입력합니다.
- 노트북의 인스턴스 타입을 선택합니다. 선택한 타입에 따라 인스턴스의 사양이 선택됩니다.
-
스토리지
- 노트북의 부트 스토리지와 데이터 스토리지 크기를 지정합니다.
- 부트 스토리지는 주피터 노트북 및 기본 가상 환경이 설치되는 스토리지입니다. 이 스토리지는 노트북을 재시작하면 초기화됩니다.
- 데이터 스토리지는
/root/easymaker디렉터리 경로에 마운트 되는 블록 스토리지입니다. 이 스토리지의 데이터는 노트북을 재시작해도 유지됩니다.
- 생성된 노트북의 스토리지 크기는 변경할 수 없으므로 생성 시 충분한 스토리지 크기로 지정하시기 바랍니다.
- 스토리지 크기는 10GB 단위로, 최대 2,040GB까지 입력할 수 있습니다.
- 필요한 경우 노트북을 연결할 NHN Cloud NAS를 연결할 수 있습니다.
- 마운트 디렉터리 이름: 노트북에 마운트 할 디렉터리 이름을 입력합니다.
- NHN Cloud NAS 경로:
nas://{NAS ID}:/{path}형식의 디렉터리 경로를 입력합니다.
- 노트북의 부트 스토리지와 데이터 스토리지 크기를 지정합니다.
-
추가 설정
- 태그: Key-Value 형식의 태그를 지정할 수 있습니다. 태그는 최대 10개까지 입력할 수 있습니다.
[주의] NHN Cloud NAS를 사용하는 경우 AI EasyMaker와 동일한 프로젝트에서 생성된 NHN Cloud NAS만 사용 가능합니다.
[참고] 노트북 생성 소요 시간 노트북 생성은 몇 분의 시간이 소요될 수 있습니다. 최초 리소스(노트북, 학습, 실험, 엔드포인트) 생성 시 서비스 환경 구성을 위해 추가로 몇 분의 시간이 더 소요됩니다.
노트북 목록
노트북 목록이 표시됩니다. 목록의 노트북을 선택하면 상세 정보를 확인하고 정보를 변경할 수 있습니다.
- 이름: 노트북 이름이 표시됩니다. 상세화면에서 변경을 클릭하면 이름을 변경할 수 있습니다.
-
상태: 노트북의 상태가 표시됩니다. 주요 상태는 아래 표를 참고해 주세요.
상태 설명 CREATE REQUESTED 노트북 생성이 요청된 상태입니다. CREATE IN PROGRESS 노트북 인스턴스를 생성 중인 상태입니다. ACTIVE (HEALTHY) 노트북 애플리케이션이 정상적으로 구동 중인 상태입니다. ACTIVE (UNHEALTHY) 노트북 애플리케이션이 정상적으로 구동되지 않은 상태입니다. 노트북을 재시작한 후에도 이 상태가 지속되면 고객 센터로 문의해 주세요. STOP IN PROGRESS 노트북을 중지 중인 상태입니다. STOPPED 노트북을 중지한 상태입니다. START IN PROGRESS 노트북을 시작 중인 상태입니다. DELETE IN PROGRESS 노트북을 삭제 중인 상태입니다. CREATE FAILED 노트북 생성 중 실패한 상태입니다. 생성이 지속적으로 실패하면 고객 센터로 문의해 주세요. STOP FAILED 노트북 중지를 실패한 상태입니다. 다시 시도해 주세요. START FAILED 노트북 시작을 실패한 상태입니다. 다시 시도해 주세요. DELETE FAILED 노트북 삭제를 실패한 상태입니다. 다시 시도해 주세요. -
작업 > 주피터 노트북 열기: 주피터 노트북 열기 버튼을 클릭하면 브라우저의 새 창으로 노트북을 엽니다. 노트북은 콘솔에 로그인한 사용자만 접근이 가능합니다.
-
태그: 노트북의 태그가 표시됩니다. 태그는 변경을 클릭하여 변경할 수 있습니다.
-
모니터링: 노트북을 선택하면 표시되는 상세 화면의 모니터링 탭에서 모니터링 대상 인스턴스 목록과 기본 지표 차트를 확인할 수 있습니다.
- 모니터링 탭은 노트북이 생성 중이거나 진행 중인 작업이 있을 때 비활성화됩니다.
사용자 가상 실행 환경 구성
AI EasyMaker 노트북 인스턴스는 머신 러닝에 필요한 다양한 라이브러리 및 커널이 설치된 기본 Conda 가상 환경을 제공합니다.
기본 Conda 가상 환경은 노트북을 중지하고 시작할 때 초기화되어 구동되지만, 사용자가 임의의 경로에 설치한 가상 환경 및 외부 라이브러리는 자동으로 초기화되지 않기 때문에 노트북을 중지하고 시작했을 때 유지되지 않습니다.
이 문제를 해결하려면, /root/easymaker/custom-conda-envs 디렉터리 경로에 가상 환경을 생성하고, 생성된 가상 환경에서 외부 라이브러리를 설치해야 합니다.
AI EasyMaker 노트북 인스턴스는 /root/easymaker/custom-conda-envs 디렉터리 경로에 생성된 가상 환경에 대해 노트북을 중지하고 시작할 때 초기화되어 구동되도록 지원합니다.
다음의 가이드를 참고하여 사용자 가상 환경을 구성해 주세요.
- 콘솔 노트북 메뉴의 주피터 노트북 열기 > 주피터 노트북 > Launcher > Terminal을 클릭합니다.
-
/root/easymaker/custom-conda-envs경로로 이동합니다.cd /root/easymaker/custom-conda-envs -
파이썬 3.8 버전의
easymaker_env라는 가상 환경을 생성하려면 다음과 같이conda create명령어를 수행합니다.conda create --prefix ./easymaker_env python=3.8 -
생성된 가상 환경은
conda env list명령어로 확인할 수 있습니다.(base) root@nb-xxxxxx-0:~# conda env list # conda environments: # /opt/intel/oneapi/intelpython/latest /opt/intel/oneapi/intelpython/latest/envs/2022.2.1 base * /opt/miniconda3 easymaker_env /root/easymaker/custom-conda-envs/easymaker_env
노트북 중지
구동 중인 노트북을 중지하거나 중지된 노트북을 시작합니다.
- 노트북 목록에서 시작 또는 중지하려는 노트북을 선택합니다.
- 노트북 시작 또는 노트북 중지를 클릭합니다.
- 요청된 작업은 취소할 수 없습니다. 계속 진행하려면 확인을 클릭합니다.
[주의] 노트북 중지 후 시작 시 가상 환경 및 외부 라이브러리 유지 방법 노트북을 중지하고 시작할 때 사용자가 생성한 가상 환경 및 외부 라이브러리가 초기화될 수 있습니다. 유지하려면 사용자 가상 실행 환경 구성을 참고하여 사용자 가상 환경을 구성해 주세요.
[참고] 노트북 시작과 중지 소요 시간 노트북 시작과 중지는 몇 분의 시간이 소요될 수 있습니다.
노트북 인스턴스 타입 변경
생성된 노트북의 인스턴스 타입을 변경합니다. 변경하려는 인스턴스 타입은 기존 인스턴스와 동일한 코어 타입의 인스턴스 타입으로만 변경이 가능합니다.
- 인스턴스 타입을 변경하려는 노트북을 선택합니다.
- 노트북이 구동 중인 상태(ACTIVE)인 경우, 노트북 중지를 클릭하여 노트북을 중지합니다.
- 인스턴스 타입 변경을 클릭합니다.
- 변경하려는 인스턴스 타입을 선택하고 확인을 클릭합니다.
[참고] 인스턴스 타입 변경 소요 시간 인스턴스 타입 변경은 몇 분의 시간이 소요될 수 있습니다.
노트북 삭제
생성된 노트북을 삭제합니다.
- 목록에서 삭제하려는 노트북을 선택합니다.
- 노트북 삭제을 클릭합니다.
- 요청된 삭제 작업은 취소할 수 없습니다. 계속 진행하려면 확인을 클릭합니다.
[참고] 스토리지 노트북을 삭제할 경우 부트 스토리지와 데이터 스토리지가 삭제됩니다. 연결한 NHN Cloud NAS는 삭제되지 않으며 NHN Cloud NAS에서 개별 삭제해야 합니다.
실험
실험은 연관된 학습을 실험으로 그룹화하여 관리합니다.
실험 생성
- 실험 생성을 클릭합니다.
- 실험 이름과 설명을 입력하고 확인을 클릭합니다.
[참고] 실험 생성 소요 시간 실험 생성은 몇 분의 시간이 소요될 수 있습니다. 최초 리소스(노트북, 학습, 실험, 엔드포인트) 생성 시 서비스 환경 구성을 위해 추가로 몇 분의 시간이 더 소요됩니다.
실험 목록
실험 목록이 표시됩니다. 목록의 실험을 선택하면 상세 정보를 확인하고 정보를 변경할 수 있습니다.
-
상태: 실험의 상태가 표시됩니다. 주요 상태는 아래 표를 참고해 주세요.
상태 설명 CREATE REQUESTED 실험 생성이 요청된 상태입니다. CREATE IN PROGRESS 실험이 생성 중인 상태입니다. CREATE FAILED 실험 생성을 실패한 상태입니다. 다시 시도해 주세요. ACTIVE 실험이 정상적으로 생성된 상태입니다. -
작업
- 텐서보드 바로가기를 클릭하면 실험에 포함된 학습의 통계 정보를 확인할 수 있는 텐서보드가 브라우저 새 창으로 열립니다. 텐서보드는 콘솔에 로그인한 사용자만 접속할 수 있습니다.
- 재시도: 실험 상태가 실패일 경우, 재시도를 클릭하여 실험을 복구할 수 있습니다.
- 학습: 학습을 선택하면 표시되는 상세 화면의 학습 탭은 실험에 포함된 학습의 목록이 표시됩니다.
실험 삭제
실험을 삭제합니다.
- 삭제할 실험을 선택합니다.
- 실험 삭제를 클릭합니다. 실험이 생성 중인 상태인 경우 실험을 삭제할 수 없습니다.
- 요청된 삭제 작업은 취소할 수 없습니다. 계속 진행하려면 확인을 클릭합니다.
[참고] 연관된 학습이 존재할 경우 실험 삭제 불가 실험과 연관된 학습이 존재하는 경우 실험을 삭제할 수 없습니다. 먼저 연관된 학습을 삭제한 후 실험을 삭제해 주세요. 연관된 학습은 삭제하려는 실험을 클릭하면 표시되는 하단의 상세화면에서 [학습] 탭을 클릭하여 목록을 확인할 수 있습니다.
학습
머신 러닝 알고리즘을 학습하고 학습 결과를 통계로 확인할 수 있는 환경을 제공합니다.
학습 생성
학습이 수행될 인스턴스와 OS 이미지를 선택하여 학습이 수행될 환경을 설정하고, 학습하려는 알고리즘 정보와 입력/출력 데이터 경로를 입력하여 학습을 진행합니다.
- 학습 템플릿: 학습 템플릿을 불러와서 학습 정보를 설정하려면 '사용'을 선택한 후, 불러올 학습 템플릿을 선택합니다.
- 기본 정보: 학습에 대한 기본 정보와 학습이 포함될 실험을 선택합니다.
- 학습 이름: 학습 이름을 입력합니다.
- 학습 설명: 설명을 입력합니다.
- 실험: 학습이 포함될 실험을 선택합니다. 실험은 연관된 학습을 그룹화합니다. 생성된 실험이 없는 경우 추가를 클릭하여 실험을 생성합니다.
-
알고리즘 정보: 학습하려는 알고리즘에 대한 정보를 입력합니다.
- 알고리즘 유형: 알고리즘 유형을 선택합니다.
- NHN Cloud 제공 알고리즘: AI EasyMaker에서 제공하는 알고리즘을 사용합니다. 제공하는 알고리즘에 대한 상세 정보는 NHN Cloud 제공 알고리즘 가이드 문서를 참고합니다.
- 알고리즘: 알고리즘을 선택합니다.
- 하이퍼파라미터: 학습에 필요한 하이퍼파라미터 값을 입력합니다. 알고리즘별 하이퍼파라미터에 대한 자세한 정보는 NHN Cloud 제공 알고리즘 가이드 문서를 참고합니다.
- 알고리즘 지표: 알고리즘에서 생성되는 지표에 대한 정보가 표시됩니다.
-
자체 알고리즘: 사용자가 작성한 알고리즘을 사용합니다.
-
알고리즘 경로
- NHN Cloud Object Storage: 알고리즘이 저장된 NHN Cloud Object Storage의 경로를 입력합니다.
- obs://{Object Storage API 엔드포인트}/{containerName}/{path} 형식으로 디렉터리 경로를 입력합니다.
- NHN Cloud Object Storage를 이용하는 경우 부록 > 1. NHN Cloud Object Storage에 AI EasyMaker 시스템 계정 권한 추가를 참고하여 권한을 설정해 주세요. 필요한 권한을 설정하지 않으면 모델 생성에 실패합니다.
- NHN Cloud NAS: 알고리즘이 저장된 NHN Cloud NAS 경로를 입력합니다.
nas://{NAS ID}:/{path} 형식으로 디렉터리 경로를 입력합니다.
- NHN Cloud Object Storage: 알고리즘이 저장된 NHN Cloud Object Storage의 경로를 입력합니다.
-
엔트리 포인트
- 엔트리 포인트는 학습이 시작되는 알고리즘 실행의 인입점입니다. 엔트리 포인트 파일명을 작성합니다.
- 엔트리 포인트 파일은 알고리즘 경로에 존재해야 합니다.
- 동일한 경로에 requirements.txt를 작성하면 스크립트에서 필요한 파이썬 패키지가 설치됩니다.
- 하이퍼파라미터
- 학습을 위한 파라미터를 추가하려면 + 버튼을 클릭하여 Key-Value 형식으로 파라미터를 입력합니다. 파라미터는 최대 100개까지 입력할 수 있습니다.
- 입력된 하이퍼파라미터는 엔트리 포인트가 실행될 때 실행 인자로 입력됩니다. 자세한 활용 방법은 부록 > 3. 하이퍼파라미터를 참고해 주세요.
-
- NHN Cloud 제공 알고리즘: AI EasyMaker에서 제공하는 알고리즘을 사용합니다. 제공하는 알고리즘에 대한 상세 정보는 NHN Cloud 제공 알고리즘 가이드 문서를 참고합니다.
- 알고리즘 유형: 알고리즘 유형을 선택합니다.
-
이미지: 학습을 실행해야 하는 환경에 맞게 인스턴스의 이미지를 선택합니다.
-
학습 리소스 정보
- 학습 인스턴스 타입: 학습을 실행할 인스턴스 타입을 선택합니다.
- 분산 노드 수: 분산 학습을 수행할 노드 수를 입력합니다. 알고리즘 코드에서 설정을 통해 분산 학습이 가능하게 할 수 있습니다. 자세한 사항은 부록 > 6. 프레임워크별 분산 학습 설정을 참고해 주세요.
- torchrun 사용 여부: Pytorch 프레임워크에서 지원하는 torchrun의 사용 여부를 선택해 주세요. 자세한 사항은 부록 > 8. torchrun 사용 방법을 참고해 주세요.
- 노드당 프로세스 개수: torchrun을 사용할 경우 노드당 프로세스 개수를 입력합니다. torchrun을 사용하면 하나의 노드에 여러 프로세스를 실행하여 분산 학습이 가능합니다. 프로세스 개수에 따라 메모리 사용량에 영향이 있습니다.
- 입력 데이터
- 데이터 세트: 학습을 실행할 데이터 세트를 입력합니다. 데이터 세트는 최대 10개까지 설정할 수 있습니다.
- 데이터 세트 이름: 데이터 세트 이름을 입력합니다.
- 데이터 경로: NHN Cloud Object Storage 또는 NHN Cloud NAS 경로를 입력합니다.
- 체크 포인트: 저장된 체크 포인트부터 학습을 진행하려는 경우 체크 포인트의 저장 경로를 입력합니다.
- NHN Cloud Object Storage 또는 NHN Cloud NAS 경로를 입력합니다.
- 데이터 세트: 학습을 실행할 데이터 세트를 입력합니다. 데이터 세트는 최대 10개까지 설정할 수 있습니다.
- 출력 데이터
- 출력 데이터: 학습의 실행 결과를 저장할 데이터 저장 경로를 입력합니다.
- NHN Cloud Object Storage 또는 NHN Cloud NAS 경로를 입력합니다.
- 체크 포인트: 알고리즘이 체크 포인트를 제공하는 경우 체크 포인트의 저장 경로를 입력합니다.
- 생성된 체크 포인트는 이전 학습으로부터 다시 학습을 재개할 때 이용할 수 있습니다.
- NHN Cloud Object Storage 또는 NHN Cloud NAS 경로를 입력합니다.
- 출력 데이터: 학습의 실행 결과를 저장할 데이터 저장 경로를 입력합니다.
- 추가 설정
- 데이터 스토리지 크기: 학습을 실행할 인스턴스의 데이터 스토리지 크기를 입력합니다.
- NHN Cloud Object Storage를 사용하는 경우에만 사용됩니다. 학습에 필요한 데이터가 모두 저장될 수 있도록 충분한 크기를 지정하시기 바랍니다.
- 최대 학습 시간: 학습이 완료될 때까지 최대 대기 시간을 지정합니다. 최대 대기 시간이 초과한 학습은 종료 처리됩니다.
- 로그 관리: 학습 진행 중 발생하는 로그를 NHN Cloud Log & Crash 서비스에 저장할 수 있습니다.
- 자세한 내용은 부록 > 2. NHN Cloud Log & Crash Search 서비스 이용 안내 및 로그 확인을 참고해 주세요.
- 태그: 태그를 추가하려면 + 버튼을 클릭하여 Key-Value 형식으로 태그를 입력합니다. 태그는 최대 10개까지 입력할 수 있습니다.
- 데이터 스토리지 크기: 학습을 실행할 인스턴스의 데이터 스토리지 크기를 입력합니다.
[주의] NHN Cloud NAS를 사용하는 경우 AI EasyMaker와 동일한 프로젝트에서 생성된 NHN Cloud NAS만 사용 가능합니다.
[주의] 학습 입력 데이터 삭제 시 학습 실패 학습이 완료되기 전 입력 데이터를 삭제하면 학습에 실패할 수 있습니다.
학습 목록
학습 목록이 표시됩니다. 목록의 학습을 선택하면 상세 정보를 확인하고 정보를 변경할 수 있습니다.
- 학습 시간: 학습이 진행된 시간이 표시됩니다.
-
상태: 학습의 상태가 표시됩니다. 주요 상태는 아래 표를 참고해 주세요.
상태 설명 CREATE REQUESTED 학습 생성을 요청한 상태입니다. CREATE IN PROGRESS 학습에 필요한 자원을 생성 중인 상태입니다. RUNNING 학습이 진행 중인 상태입니다. STOPPED 학습이 사용자의 요청으로 중지된 상태입니다. COMPLETE 학습이 정상적으로 완료된 상태입니다. STOP IN PROGRESS 학습이 중지 중인 상태입니다. FAIL TRAIN 학습 진행 중 실패한 상태입니다. 자세한 실패 정보는 로그 관리가 활성화된 경우, Log & Crash Search 로그를 통해 확인할 수 있습니다. CREATE FAILED 학습 생성을 실패한 상태입니다. 생성이 지속적으로 실패하면 고객 센터로 문의해 주세요. FAIL TRAIN IN PROGRESS, COMPLETE IN PROGRESS 학습에 사용된 리소스를 정리 중인 상태입니다. -
작업
- 텐서보드 바로가기: 학습의 통계 정보를 확인할 수 있는 텐서보드가 브라우저 새 창으로 열립니다.
텐서보드 로그를 남기는 방법은 부록 > 5. 텐서보드 활용을 위한 지표 로그 저장을 참고해 주세요. 텐서보드는 콘솔에 로그인한 사용자만 접속할 수 있습니다. - 학습 중지: 진행 중인 학습을 중지할 수 있습니다.
- 텐서보드 바로가기: 학습의 통계 정보를 확인할 수 있는 텐서보드가 브라우저 새 창으로 열립니다.
-
하이퍼파라미터: 학습을 선택하면 표시되는 상세 화면의 하이퍼파라미터 탭에서 학습에 설정한 하이퍼파라미터 값을 확인할 수 있습니다.
-
모니터링: 학습을 선택하면 표시되는 상세 화면의 모니터링 탭에서 모니터링 대상 인스턴스 목록과 기본 지표 차트를 확인할 수 있습니다.
- 모니터링 탭은 학습이 생성 중인 상태에는 비활성화됩니다.
학습 복사
기존 학습과 동일한 설정으로 새로운 학습을 생성합니다.
- 복사하려는 학습을 선택합니다.
- 학습 복사를 클릭합니다.
- 기존 학습과 동일한 설정으로 학습 생성 화면이 표시됩니다.
- 설정을 변경하려는 정보가 있다면 변경한 후 학습 생성을 클릭하여 학습을 생성합니다.
학습에서 모델 생성하기
완료된 상태의 학습으로 모델을 생성합니다.
- 모델로 생성하려는 학습을 선택합니다.
- 모델 생성을 클릭합니다. 완료(COMPLETE) 상태의 학습만 모델로 생성할 수 있습니다.
- 모델 생성 페이지로 이동됩니다. 내용을 확인 후 모델 생성을 클릭하여 모델을 생성합니다. 모델 생성에 대한 자세한 내용은 모델 문서를 참고해 주세요.
학습 삭제
학습을 삭제합니다.
- 삭제하려는 학습을 선택합니다.
- 학습 삭제를 클릭합니다. 진행 중인 학습은 중지 후 삭제할 수 있습니다.
- 요청된 삭제 작업은 취소할 수 없습니다. 계속 진행하려면 확인을 클릭합니다.
[참고] 연관된 모델이 존재할 경우 학습 삭제 불가 삭제하려는 학습으로 생성된 모델이 존재하는 경우 학습을 삭제할 수 없습니다. 모델을 먼저 삭제한 후 학습을 삭제해 주세요.
하이퍼파라미터 튜닝
하이퍼파라미터 튜닝은 모델의 예측 정확도를 최대화하기 위해 하이퍼파라미터 값을 최적화하는 과정입니다. 만약 이 기능을 사용하지 않으면, 많은 학습 작업을 직접 실행하면서 하이퍼파라미터를 수동으로 조정하여 최적의 값들을 찾아야 합니다.
하이퍼파라미터 튜닝 생성
하이퍼파라미터 튜닝 작업을 구성하는 방법입니다.
- 학습 템플릿
- 사용: 학습 템플릿 사용 여부를 선택합니다. 학습 템플릿을 사용하면 하이퍼파라미터 튜닝의 일부 구성 값이 미리 지정해 둔 값으로 채워집니다.
- 학습 템플릿: 하이퍼파라미티 튜닝의 일부 구성 값을 자동으로 입력하는 데 사용할 학습 템플릿을 선택합니다.
- 기본 정보
- 하이퍼파라미터 튜닝 이름: 하이퍼파라미터 튜닝 작업의 이름을 입력합니다.
- 설명: 하이퍼파라미터 튜닝 작업에 대한 설명이 필요한 경우에 입력합니다.
- 실험: 하이퍼파라미터 튜닝이 포함될 실험을 선택합니다. 실험은 연관된 하이퍼파라미터 튜닝을 그룹화합니다. 생성된 실험이 없는 경우 추가를 클릭하여 실험을 생성합니다.
- 튜닝 전략
- 전략 이름: 어떤 전략을 사용해서 최적의 하이퍼파라미터를 찾을지 선택합니다.
- 난수 시드: 난수 생성을 결정합니다. 재현 가능한 결과를 위해 고정된 값으로 지정합니다.
- 알고리즘 정보: 학습하려는 알고리즘에 대한 정보를 입력합니다.
- 알고리즘 유형: 알고리즘 유형을 선택합니다.
- NHN Cloud 제공 알고리즘: AI EasyMaker에서 제공하는 알고리즘을 사용합니다. 제공하는 알고리즘에 대한 상세 정보는 NHN Cloud 제공 알고리즘 가이드 문서를 참고합니다.
- 알고리즘: 알고리즘을 선택합니다.
- 하이퍼파라미터 스펙: 하이퍼파라미터 튜닝에 사용할 하이퍼파라미터 값 범위를 입력합니다. 알고리즘별 하이퍼파라미터에 대한 자세한 정보는 NHN Cloud 제공 알고리즘 가이드 문서를 참고합니다.
- 이름: 어떤 하이퍼파라미터를 튜닝할지 정의합니다. 알고리즘별로 정해져 있습니다.
- 유형: 하이퍼파라미터의 데이터 유형을 선택합니다. 알고리즘별로 정해져 있습니다.
- 값/범위
- Min: 최솟값을 정의합니다.
- Max: 최댓값을 정의합니다.
- Step: "Grid" 튜닝 전략을 사용할 때 하이퍼파라미터 값의 변화 크기를 결정합니다.
- 알고리즘 지표: 알고리즘에서 생성되는 지표에 대한 정보가 표시됩니다.
- 자체 알고리즘: 사용자가 작성한 알고리즘을 사용합니다.
- 알고리즘 경로
- NHN Cloud Object Storage: 알고리즘이 저장된 NHN Cloud Object Storage의 경로를 입력합니다.
- obs://{Object Storage API 엔드포인트}/{containerName}/{path} 형식으로 디렉터리 경로를 입력합니다.
- NHN Cloud Object Storage를 이용하는 경우 부록 > 1. NHN Cloud Object Storage에 AI EasyMaker 시스템 계정 권한 추가를 참고하여 권한을 설정해 주세요. 필요한 권한을 설정하지 않으면 모델 생성에 실패합니다.
- NHN Cloud NAS: 알고리즘이 저장된 NHN Cloud NAS 경로를 입력합니다.
nas://{NAS ID}:/{path} 형식으로 디렉터리 경로를 입력합니다.
- NHN Cloud Object Storage: 알고리즘이 저장된 NHN Cloud Object Storage의 경로를 입력합니다.
- 엔트리 포인트
- 엔트리 포인트는 학습이 시작되는 알고리즘 실행의 인입점입니다. 엔트리 포인트 파일명을 작성합니다.
- 엔트리 포인트 파일은 알고리즘 경로에 존재해야 합니다.
- 동일한 경로에 requirements.txt를 작성하면 스크립트에서 필요한 파이썬 패키지가 설치됩니다.
- 하이퍼파라미터 스펙
- 이름: 어떤 하이퍼파라미터를 튜닝할지 정의합니다.
- 유형: 하이퍼파라미터의 데이터 유형을 선택합니다.
- 값/범위
- Min: 최솟값을 정의합니다.
- Max: 최댓값을 정의합니다.
- Step: "Grid" 튜닝 전략을 사용할 때 하이퍼파라미터 값의 변화 크기를 결정합니다.
- Comma-separated values: 정적인 값을 사용해서 하이퍼파라미터를 튜닝합니다(예: sgd, adam).
- 알고리즘 경로
- NHN Cloud 제공 알고리즘: AI EasyMaker에서 제공하는 알고리즘을 사용합니다. 제공하는 알고리즘에 대한 상세 정보는 NHN Cloud 제공 알고리즘 가이드 문서를 참고합니다.
- 알고리즘 유형: 알고리즘 유형을 선택합니다.
- 이미지: 학습을 실행해야 하는 환경에 맞게 인스턴스의 이미지를 선택합니다.
- 학습 리소스 정보
- 학습 인스턴스 타입: 학습을 실행할 인스턴스 타입을 선택합니다.
- 학습 인스턴스 수: 학습을 수행할 인스턴스 수입니다. 학습 인스턴스 수는 '분산 노드 수x병렬 학습 수'입니다.
- 분산 노드 수: 분산 학습을 수행할 노드 수를 입력합니다. 알고리즘 코드에서 설정을 통해 분산 학습이 가능하게 할 수 있습니다. 자세한 사항은 부록 > 6. 프레임워크별 분산 학습 설정을 참고해 주세요.
- 병렬 학습 수: 동시에 병렬로 수행할 학습 수를 입력합니다.
- torchrun 사용 여부: Pytorch 프레임워크에서 지원하는 torchrun의 사용 여부를 선택해 주세요. 자세한 사항은 부록 > 8. torchrun 사용 방법을 참고해 주세요.
- 노드당 프로세스 개수: torchrun을 사용할 경우 노드당 프로세스 개수를 입력합니다. torchrun을 사용하면 하나의 노드에 여러 프로세스를 실행하여 분산 학습이 가능합니다. 프로세스 개수에 따라 메모리 사용량에 영향이 있습니다.
- 입력 데이터
- 데이터 세트: 학습을 실행할 데이터 세트를 입력합니다. 데이터 세트는 최대 10개까지 설정할 수 있습니다.
- 데이터 세트 이름: 데이터 세트 이름을 입력합니다.
- 데이터 경로: NHN Cloud Object Storage 또는 NHN Cloud NAS 경로를 입력합니다.
- 체크 포인트: 저장된 체크 포인트부터 학습을 진행하려는 경우 체크 포인트의 저장 경로를 입력합니다.
- NHN Cloud Object Storage 또는 NHN Cloud NAS 경로를 입력합니다.
- 데이터 세트: 학습을 실행할 데이터 세트를 입력합니다. 데이터 세트는 최대 10개까지 설정할 수 있습니다.
- 출력 데이터
- 출력 데이터: 학습의 실행 결과를 저장할 데이터 저장 경로를 입력합니다.
- NHN Cloud Object Storage 또는 NHN Cloud NAS 경로를 입력합니다.
- 체크 포인트: 알고리즘이 체크 포인트를 제공하는 경우 체크 포인트의 저장 경로를 입력합니다.
- 생성된 체크 포인트는 이전 학습으로부터 다시 학습을 재개할 때 이용할 수 있습니다.
- NHN Cloud Object Storage 또는 NHN Cloud NAS 경로를 입력합니다.
- 출력 데이터: 학습의 실행 결과를 저장할 데이터 저장 경로를 입력합니다.
- 지표
- 지표 이름: 학습 코드가 출력하는 로그 중에 어떤 지표를 수집할지 정의합니다.
- 지표 형식: 지표를 수집하는 데 사용할 정규 표현식을 입력합니다. 학습 알고리즘이 정규 표현식에 맞게 지표를 출력해야 합니다.
- 목표 지표
- 지표 이름: 어떤 지표를 최적화하는 게 목표인지 선택합니다.
- 목표 지표 유형: 최적화 유형을 선택합니다.
- 목표값: 목표 지표가 이 값에 도달하면 튜닝 작업이 종료됩니다.
- 튜닝 리소스 구성
- 최대 실패 학습 수: 실패한 학습의 최대 개수를 정의합니다. 실패한 학습의 개수가 이 값에 도달하면 튜닝이 실패로 종료됩니다.
- 최대 학습 수: 최대 학습 수를 정의합니다. 자동 실행된 학습의 개수가 이 값에 도달할 때까지 튜닝이 실행됩니다.
- 학습 조기 중지
- 이름: 학습이 계속 진행되어도 모델이 더 이상 좋아지지 않으면 학습을 조기에 종료합니다.
- Min Trainings Required: 중간값을 계산할 때 몇 개의 학습으로부터 목표 지표 값을 가져올지 정의합니다.
- Start Step: 몇 번째 학습 단계부터 조기 중지를 적용할지 설정합니다.
- 추가 설정
- 데이터 스토리지 크기: 학습을 실행할 인스턴스의 데이터 스토리지 크기를 입력합니다.
- NHN Cloud Object Storage를 사용하는 경우에만 사용됩니다. 학습에 필요한 데이터가 모두 저장될 수 있도록 충분한 크기를 지정하시기 바랍니다.
- 최대 진행 시간: 학습이 완료될 때까지 최대 진행 시간을 지정합니다. 최대 진행 시간이 초과한 학습은 종료 처리됩니다.
- 로그 관리: 학습 진행 중 발생하는 로그를 NHN Cloud Log & Crash 서비스에 저장할 수 있습니다.
- 자세한 내용은 부록 > 2. NHN Cloud Log & Crash Search 서비스 이용 안내 및 로그 확인을 참고해 주세요.
- 태그: 태그를 추가하려면 + 버튼을 클릭하여 Key-Value 형식으로 태그를 입력합니다. 태그는 최대 10개까지 입력할 수 있습니다.
- 데이터 스토리지 크기: 학습을 실행할 인스턴스의 데이터 스토리지 크기를 입력합니다.
[주의] NHN Cloud NAS를 사용하는 경우 AI EasyMaker와 동일한 프로젝트에서 생성된 NHN Cloud NAS만 사용 가능합니다.
[주의] 학습 입력 데이터 삭제 시 학습 실패 학습이 완료되기 전 입력 데이터를 삭제하면 학습에 실패할 수 있습니다.
하이퍼파라미터 튜닝 목록
하이퍼파라미터 튜닝 목록이 표시됩니다. 목록의 하이퍼파라미터 튜닝을 선택하면 상세 정보를 확인하고 정보를 변경할 수 있습니다.
- 소요 시간: 하이퍼파라미터 튜닝에 소요된 시간을 표시합니다.
- 완료한 학습: 하이퍼파라미터 튜닝에 의해 자동 생성된 학습 중에 완료한 학습 수를 나타냅니다.
- 진행 중인 학습: 진행 중인 학습 수를 나타냅니다.
- 실패한 학습: 실패한 학습 수를 나타냅니다.
- 최고 학습: 하이퍼파라미터 튜닝에 의해 자동 생성된 학습 중에 최고의 목표 지표 값을 기록한 학습의 목표 지표 정보를 나타냅니다.
-
상태: 하이퍼파라미터 튜닝의 상태가 표시됩니다. 주요 상태는 아래 표를 참고해 주세요.
상태 설명 CREATE REQUESTED 하이퍼파라미터 튜닝 생성을 요청한 상태입니다. CREATE IN PROGRESS 하이퍼파라미터 튜닝에 필요한 자원을 생성 중인 상태입니다. RUNNING 하이퍼파라미터 튜닝이 진행 중인 상태입니다. STOPPED 하이퍼파라미터 튜닝이 사용자의 요청으로 중지된 상태입니다. COMPLETE 하이퍼파라미터 튜닝이 정상적으로 완료된 상태입니다. STOP IN PROGRESS 하이퍼파라미터 튜닝이 중지 중인 상태입니다. FAIL HYPERPARAMETER TUNING 하이퍼파라미터 튜닝 진행 중에 실패한 상태입니다. 자세한 실패 정보는 로그 관리가 활성화된 경우, Log & Crash Search 로그를 통해 확인할 수 있습니다. CREATE FAILED 하이퍼파라미터 튜닝 생성을 실패한 상태입니다. 생성이 지속적으로 실패하면 고객 센터로 문의해 주세요. FAIL HYPERPARAMETER TUNING IN PROGRESS, COMPLETE IN PROGRESS, STOP IN PROGRESS 하이퍼파라미터 튜닝에 사용된 리소스를 정리 중인 상태입니다. -
상태 상세 정보:
COMPLETE상태의 괄호 안 내용은 상태의 상세 정보입니다. 주요 상세 정보는 아래 표를 참고해 주세요.상세 정보 설명 GoalReached 하이퍼파라미터 튜닝의 학습이 목표 값에 도달하여 완료되었을 때의 상세 정보입니다. MaxTrialsReached 하이퍼파라미터 튜닝이 최대 학습 수에 도달하여 완료되었을 때의 상세 정보입니다. SuggestionEndReached 하이퍼파라미터 튜닝의 탐색 알고리즘이 모든 하이퍼파라미터를 탐색하였을 때의 상세 정보입니다. - 작업 - 텐서보드 바로가기: 학습의 통계 정보를 확인할 수 있는 텐서보드가 브라우저 새 창으로 열립니다. 텐서보드 로그를 남기는 방법은 부록 > 5. 텐서보드 활용을 위한 지표 로그 저장을 참고해 주세요. 텐서보드는 콘솔에 로그인한 사용자만 접속할 수 있습니다. - 하이퍼파라미터 튜닝 중지: 진행 중인 하이퍼파라미터 튜닝을 중지할 수 있습니다. -
모니터링: 하이퍼파라미터 튜닝을 선택하면 표시되는 상세 화면의 모니터링 탭에서 모니터링 대상 인스턴스 목록과 기본 지표 차트를 확인할 수 있습니다.
- 모니터링 탭은 하이퍼파라미터 튜닝이 생성 중인 상태에는 비활성화됩니다.
하이퍼파라미터 튜닝의 학습 목록
하이퍼파라미터 튜닝에 의해 자동 생성된 학습 목록이 표시됩니다. 목록의 학습을 선택하면 상세 정보를 확인할 수 있습니다.
- 목표 지표 값: 목표 지표 값을 나타냅니다.
-
상태: 하이퍼파라미터 튜닝에 의해 자동 생성된 학습의 상태가 표시됩니다. 주요 상태는 아래 표를 참고해 주세요.
상태 설명 CREATED 학습이 생성된 상태입니다. RUNNING 학습이 진행 중인 상태입니다. SUCCEEDED 학습이 정상적으로 완료된 상태입니다. KILLED 학습이 시스템에 의해 중지된 상태입니다. FAILED 학습 진행 중에 실패한 상태입니다. 자세한 실패 정보는 로그 관리가 활성화된 경우, Log & Crash Search 로그를 통해 확인할 수 있습니다. METRICS_UNAVAILABLE 목표 지표를 수집할 수 없는 상태입니다. EARLY_STOPPED 학습 진행 중 성능(목표 지표)이 더 좋아지지 않아 조기 중지된 상태입니다.
하이퍼파라미터 튜닝 복사
기존 하이퍼파라미터 튜닝과 동일한 설정으로 새로운 하이퍼파라미터 튜닝을 생성합니다.
- 복사하려는 하이퍼파라미터 튜닝을 선택합니다.
- 하이퍼파라미터 튜닝 복사를 클릭합니다.
- 기존 하이퍼파라미터 튜닝과 동일한 설정으로 하이퍼파라미터 튜닝 생성 화면이 표시됩니다.
- 설정을 변경하려는 정보가 있다면 변경한 후 하이퍼파라미터 튜닝 생성을 클릭하여 하이퍼파라미터 튜닝을 생성합니다.
하이퍼파라미터 튜닝에서 모델 생성하기
완료된 상태의 하이퍼파라미터 튜닝의 최고 학습으로 모델을 생성합니다.
- 모델로 생성하려는 하이퍼파라미터 튜닝을 선택합니다.
- 모델 생성을 클릭합니다. 완료(COMPLETE) 상태의 하이퍼파라미터 튜닝만 모델로 생성할 수 있습니다.
- 모델 생성 페이지로 이동됩니다. 내용을 확인 후 모델 생성을 클릭하여 모델을 생성합니다. 모델 생성에 대한 자세한 내용은 모델 문서를 참고해 주세요.
하이퍼파라미터 튜닝 삭제
하이퍼파라미터 튜닝을 삭제합니다.
- 삭제하려는 하이퍼파라미터 튜닝을 선택합니다.
- 하이퍼파라미터 튜닝 삭제를 클릭합니다. 진행 중인 하이퍼파라미터 튜닝은 중지 후 삭제할 수 있습니다.
- 요청된 삭제 작업은 취소할 수 없습니다. 계속 진행하려면 확인을 클릭합니다.
[참고] 연관된 모델이 존재할 경우 하이퍼파라미터 튜닝 삭제 불가 삭제하려는 하이퍼파라미터 튜닝으로 생성된 모델이 존재하는 경우 하이퍼파라미터 튜닝을 삭제할 수 없습니다. 모델을 먼저 삭제한 후 하이퍼파라미터 튜닝을 삭제해 주세요.
학습 템플릿
학습 템플릿을 미리 만들어 두면 학습이나 하이퍼파라미터 튜닝을 생성할 때 템플릿에 입력해 둔 값을 가져올 수 있습니다.
학습 템플릿 생성
학습 템플릿에 설정할 수 있는 정보는 학습 생성을 참고해 주세요.
학습 템플릿 목록
학습 템플릿 목록이 표시됩니다. 목록의 학습 템플릿을 선택하면 상세 정보를 확인하고 정보를 변경할 수 있습니다.
- 작업
- 변경: 학습 템플릿 정보를 변경할 수 있습니다.
- 하이퍼파라미터: 학습 템플릿을 선택하면 표시되는 상세 화면의 하이퍼파라미터 탭에서 학습 템플릿에 설정한 하이퍼파라미터 이름을 확인할 수 있습니다.
학습 템플릿 복사
기존 학습 템플릿과 동일한 설정으로 새로운 학습 템플릿을 생성합니다.
- 복사하려는 학습 템플릿을 선택합니다.
- 학습 템플릿 복사를 클릭합니다.
- 기존 학습 템플릿과 동일한 설정으로 학습 템플릿 생성 화면이 표시됩니다.
- 설정을 변경하려는 정보가 있다면 변경한 후 학습 템플릿 생성을 클릭하여 학습 템플릿을 생성합니다.
학습 템플릿 삭제
학습 템플릿을 삭제합니다.
- 삭제하려는 학습 템플릿을 선택합니다.
- 학습 템플릿 삭제를 클릭합니다.
- 요청된 삭제 작업은 취소할 수 없습니다. 계속 진행하려면 확인을 클릭합니다.
모델
AI EasyMaker의 학습 결과의 모델 또는 외부의 모델을 아티팩트로 관리할 수 있습니다.
모델 생성
- 기본 정보: 모델의 기본 정보를 입력합니다.
- 이름: 모델 이름을 입력합니다.
- 모델의 프레임워크 종류가 PyTorch인 경우, PyTorch 모델 이름과 동일한 모델 이름을 입력해야 합니다.
- 설명: 모델 설명을 입력합니다.
- 이름: 모델 이름을 입력합니다.
- 프레임워크 정보: 모델의 프레임워크 정보를 입력합니다.
- 프레임워크: 모델의 프레임워크를 TensorFlow 또는 PyTorch 중 선택합니다.
- 프레임워크 버전: 모델 프레임워크의 버전을 입력합니다.
- 모델 정보: 모델의 아티팩트가 저장된 저장소를 입력합니다.
- NHN Cloud Object Storage: 모델 아티팩트가 저장된 Object Storage 경로를 입력합니다.
obs://{Object Storage API 엔드포인트}/{containerName}/{path}형식으로 디렉터리 경로를 입력합니다.- NHN Cloud Object Storage를 이용하는 경우 부록 > 1. NHN Cloud Object Storage에 AI EasyMaker 시스템 계정 권한 추가를 참고하여 권한을 설정해 주세요. 권한을 설정하지 않으면 모델의 아티팩트에 접근이 불가하여 모델 생성에 실패합니다.
- NHN Cloud NAS: 모델 아티팩트가 저장된 NHN Cloud NAS 경로를 입력합니다.
nas://{NAS ID}:/{path}형식으로 디렉터리 경로를 입력합니다.
- NHN Cloud Object Storage: 모델 아티팩트가 저장된 Object Storage 경로를 입력합니다.
- 추가 설정: 모델의 추가 정보를 입력합니다.
- 태그: 태그를 추가하려면 + 버튼을 클릭하여 Key-Value 형식으로 태그를 입력합니다. 태그는 최대 10개까지 입력할 수 있습니다.
[주의] NHN Cloud NAS를 사용하는 경우 AI EasyMaker와 동일한 프로젝트에서 생성된 NHN Cloud NAS만 사용 가능합니다.
[주의] 저장소의 모델 아티팩트 유지 저장소에 저장된 모델 아티팩트를 유지하지 않으면, 해당 모델의 엔드포인트 생성이 실패합니다.
모델 목록
모델 목록이 표시됩니다. 목록의 모델을 선택하면 상세 정보를 확인하고 정보를 변경할 수 있습니다.
- 이름: 모델 이름과 설명이 표시됩니다. 모델 이름과 설명은 변경을 클릭하여 변경할 수 있습니다.
- 태그: 모델의 태그가 표시됩니다. 태그는 변경을 클릭하여 변경할 수 있습니다.
- 모델 아티팩트 경로: 모델의 아티팩트가 저장된 저장소가 표시됩니다.
- 학습 이름: 학습에서 생성된 모델의 경우, 기반이 되는 학습의 이름이 표시됩니다.
- 학습 ID: 학습에서 생성된 모델의 경우, 기반이 되는 학습의 아이디가 표시됩니다.
- 프레임워크: 모델의 프레임워크 정보가 표시됩니다.
모델에서 엔드포인트 생성하기
선택한 모델을 서빙할 수 있는 엔드포인트를 생성합니다.
- 엔드포인트로 생성하려는 모델을 목록에서 선택합니다.
- 엔드포인트 생성을 클릭합니다.
- 엔드포인트 생성 페이지로 이동됩니다. 내용을 확인 후 엔드포인트 생성을 클릭하여 모델을 생성합니다. 엔드포인트 생성에 대한 자세한 내용은 엔드포인트 문서를 참고해 주세요.
모델 삭제
모델을 삭제합니다.
- 목록에서 삭제하려는 모델을 선택합니다.
- 모델 삭제을 클릭합니다.
- 요청된 삭제 작업은 취소할 수 없습니다. 계속 진행하려면 확인을 클릭합니다.
[참고] 연관된 엔드포인트가 존재할 경우 모델 삭제 불가 삭제하려는 모델로 생성된 엔드포인트가 존재하는 경우, 모델을 삭제할 수 없습니다. 삭제하려면 먼저 해당 모델로 생성된 엔드포인트를 삭제한 후 모델을 삭제해 주세요.
엔드포인트
모델을 서빙할 수 있는 엔드포인트를 생성하고 관리합니다.
엔드포인트 생성
- API Gateway 서비스 활성화
- AI EasyMaker 엔드포인트는 NHN Cloud API Gateway 서비스를 통해 API 엔드포인트를 생성하고 API를 관리합니다. 엔드포인트 기능을 이용하려면 API Gateway 서비스를 반드시 활성화해야 합니다.
- API Gateway 서비스에 대한 자세한 내용과 요금은 다음의 문서를 확인하시기 바랍니다.
- 엔드포인트: 신규 또는 기존 엔드포인트에 스테이지를 추가할지 선택합니다.
- 신규 엔드포인트로 생성: 신규 엔드포인트를 생성합니다. API Gateway에 신규 서비스와 기본 스테이지로 엔드포인트가 생성됩니다.
- 기존 엔드포인트에서 신규 스테이지 추가: 기존 엔드포인트의 API Gateway의 서비스에 신규 스테이지로 엔드포인트가 생성됩니다. 스테이지를 추가할 기존 엔드포인트를 선택합니다.
- 엔드포인트 이름: 엔드포인트 이름을 입력합니다. 엔드포인트 이름은 중복될 수 없습니다.
- 스테이지 이름: 기존 엔드포인트에서 신규 스테이지를 추가하는 경우, 신규 스테이지 이름을 입력합니다. 스테이지 이름은 중복될 수 없습니다.
- 설명: 엔드포인트 스테이지 설명을 입력합니다.
- 스테이지 리소스 정보: 엔드포인트에 배포할 모델 아티팩트의 정보를 입력합니다.
- 모델: 엔드포인트에 배포하려는 모델을 선택합니다. 모델을 생성하지 않은 경우 모델을 먼저 생성하시기 바랍니다.
- API Gateway 리소스 경로: 배포되는 모델의 API 리소스 경로를 입력합니다. 예를 들어
/inference로 설정한 경우POST https://{enpdoint-domain}/inference로 추론 API를 요청할 수 있습니다. - 파드 수: 스테이지 리소스의 파드 수를 입력합니다.
- 설명: 스테이지 리소스 설명을 입력합니다.
- 인스턴스 정보: 모델이 서빙될 인스턴스 정보를 입력합니다.
- 인스턴스 타입: 인스턴스 타입을 선택합니다.
- 인스턴스 개수: 인스턴스의 구동 수를 입력합니다.
- 오토스케일러: 오토스케일러는 리소스 사용량 정책에 따라 노드 수를 자동으로 조정하는 기능입니다. 오토스케일러는 스테이지 단위로 설정됩니다.
- 사용/사용 안 함: 오토스케일러 사용 여부를 선택합니다. 사용하는 경우 인스턴스 부하에 따라 인스턴스 수가 스케일 인 또는 아웃됩니다.
- 최소 노드 수: 감축 가능한 최소 노드 수
- 최대 노드 수: 증설 가능한 최대 노드 수
- 감축: 노드 감축 활성 여부 설정
- 리소스 사용량 임계치: 감축의 기준인 리소스 사용량 임계 영역의 기준값
- 임계 영역 유지 시간(분): 감축 대상이 될 노드의 임계치 이하의 리소스 사용량 유지 시간
- 증설 후 감축 지연 시간(분): 노드 증설 후 감축 대상 노드로 모니터링하기 시작까지의 지연 시간
- 추가 설정 > 태그: 태그를 추가하려면 + 버튼을 클릭하여 Key-Value 형식으로 태그를 입력합니다. 태그는 최대 10개까지 입력할 수 있습니다.
[참고] 엔드포인트 생성 소요 시간 엔드포인트 생성은 몇 분의 시간이 소요될 수 있습니다. 최초 리소스(노트북, 학습, 실험, 엔드포인트) 생성 시 서비스 환경 구성을 위해 추가로 몇 분의 시간이 더 소요됩니다.
[참고] 엔드포인트 생성 시 API Gateway 서비스 리소스 제공 제약 신규 엔드포인트 생성을 하면 API Gateway 서비스를 신규 생성합니다. 기존 엔드포인트에서 신규 스테이지 추가를 하면 API Gateway 서비스에 신규 스테이지를 생성합니다. API Gateway 서비스 리소스 제공 정책의 리소스 제공 정책을 초과한 경우, AI EasyMaker에서의 엔드포인트 생성이 불가할 수 있습니다. 이 경우 API Gateway 서비스 리소스 쿼터를 조정하시기 바랍니다.
엔드포인트 목록
엔드포인트 목록이 표시됩니다. 목록의 엔드포인트를 선택하면 상세 정보를 확인하고 정보를 변경할 수 있습니다.
- 기본 스테이지 URL: 엔드포인트의 스테이지 중 기본 스테이지의 URL이 표시됩니다.
-
상태: 엔드포인트의 상태입니다. 주요 상태는 아래 표를 참고해 주세요.
상태 설명 CREATE REQUESTED 엔드포인트 생성이 요청된 상태입니다. CREATE IN PROGRESS 엔드포인트를 생성 중인 상태입니다. UPDATE IN PROGRESS 엔드포인트의 스테이지 일부가 처리 중인 작업이 있는 상태입니다.
엔드포인트 스테이지 목록에서 스테이지별 작업 상태를 확인할 수 있습니다.DELETE IN PROGRESS 엔드포인트를 삭제 중인 상태입니다. ACTIVE 엔드포인트가 정상적으로 구동 중인 상태입니다. CREATE FAILED 엔드포인트 생성에 실패한 상태입니다.
엔드포인트를 삭제 후 다시 생성해야 합니다. 생성 실패 상태가 반복되면 고객 센터로 문의해 주세요.UPDATE FAILED 엔드포인트의 스테이지 일부가 정상적으로 서비스되지 않는 상태입니다. 문제가 되는 스테이지를 삭제 후 다시 생성해야 합니다. -
API Gateway 상태: 엔드포인트 기본 스테이지의 API Gateway 상태 정보가 표시됩니다. 주요 상태는 아래 표를 참고해 주세요.
상태 설명 CREATE IN PROGRESS API Gateway 리소스를 생성 중인 상태입니다. STAGE DEPLOYING API Gateway 기본 스테이지가 배포 중인 상태입니다. ACTIVE API Gateway 기본 스테이지가 정상적으로 배포되어 활성화된 상태입니다. NOT FOUND: STAGE 엔드포인트의 기본 스테이지를 찾을 수 없는 상태입니다.
API Gateway 콘솔에서 스테이지가 존재하는지 확인해 주세요.
스테이지가 삭제된 경우 삭제된 API Gateway 스테이지는 복구할 수 없으며, 엔드포인트를 삭제한 후 다시 생성해야 합니다.NOT FOUND: STAGE DEPLOY RESULT 엔드포인트 기본 스테이지의 배포 상태를 찾을 수 없는 상태입니다. .
API Gateway 콘솔에서 기본 스테이지가 배포된 상태인지 확인해 주세요.STAGE DEPLOY FAIL API Gateway 기본 스테이지가 배포 실패한 상태입니다.
[참고] 스테이지의 API Gateway '배포 실패' 상태인 경우 복구 방법을 참고하여 배포 실패 상태를 복구할 수 있습니다.
엔드포인트 스테이지 생성
기존 엔드포인트에 신규 스테이지를 추가합니다. 신규 스테이지를 생성하여 기본 스테이지의 영향 없이 신규 스테이지를 테스트할 수 있습니다.
- 엔드포인트 목록에서 엔드포인트 이름을 클릭합니다.
- + 스테이지 생성을 클릭합니다.
- 기존 엔드포인트에서 신규 스테이지 추가가 자동 선택되며, 설정 방법은 엔드포인트 생성 내용과 동일합니다.
- 요청된 삭제 작업은 취소할 수 없습니다. 계속 진행하려면 확인을 클릭합니다.
엔드포인트 스테이지 목록
엔드포인트 하위에 생성된 스테이지 목록이 표시됩니다. 목록의 스테이지를 선택하면 상세 정보를 확인할 수 있습니다.
-
상태: 엔드포인트 스테이지의 상태가 표시됩니다. 주요 상태는 아래 표를 참고해 주세요.
상태 설명 CREATE REQUESTED 엔드포인트 스테이지 생성이 요청된 상태입니다. CREATE IN PROGRESS 엔드포인트 스테이지를 생성 중인 상태입니다. DEPLOY IN PROGRESS 엔드포인트 스테이지에 모델을 배포 중인 상태입니다. DELETE IN PROGRESS 엔드포인트 스테이지를 삭제 중인 상태입니다. ACTIVE 엔드포인트 스테이지가 정상적으로 구동 중인 상태입니다. CREATE FAILED 엔드포인트 스테이지 생성에 실패한 상태입니다. 다시 시도해 주세요. DEPLOY FAILED 엔드포인트 스테이지 배포에 실패한 상태입니다. 다시 생성을 시도해 주세요. -
API Gateway 상태: 엔드포인트 스테이지가 배포된 API Gateway의 스테이지 상태가 표시됩니다.
- 스테이지 기본 스테이지 여부: 기본 스테이지 여부가 표시됩니다.
- 스테이지 URL: 모델이 서빙된 API Gateway의 스테이지 URL이 표시됩니다.
- API Gateway 설정 보기: AI EasyMaker가 API Gateway 스테이지에 배포한 설정을 확인하려면, 설정 보기을 클릭합니다.
- API Gateway 통계 보기: 엔드포인트의 API 통계를 보려면 통계 보기를 클릭합니다.
- 인스턴스 타입: 모델이 서빙되는 엔드포인트 인스턴스 타입이 표시됩니다.
- 실행 중인 워크 노드/파드 수: 엔드포인트에서 사용 중인 노드와 파드 수가 표시됩니다.
- 스테이지 리소스: 스테이지에 배포된 모델 아티팩트 정보가 표시됩니다.
- 모니터링: 엔드포인트 스테이지를 선택하면 표시되는 상세 화면의 모니터링 탭에서 모니터링 대상 인스턴스 목록과 기본 지표 차트를 확인할 수 있습니다.
- 모니터링 탭은 엔드포인트 스테이지가 생성 중인 상태에는 비활성화됩니다.
- API 통계: 엔드포인트 스테이지를 선택하면 표시되는 상세 화면의 API 통계 탭에서 엔드포인트 스테이지의 API 통계 정보를 확인할 수 있습니다.
- API 통계 탭은 엔드포인트 스테이지가 생성 중인 상태에는 비활성화됩니다.
[주의] AI EasyMaker가 생성한 API Gateway의 설정 변경 시 주의할 점 AI EasyMaker는 엔드포인트 생성 또는 엔드포인트 스테이지 생성을 하면 엔드포인트에 대한 API Gateway의 서비스와 스테이지를 생성합니다. AI EasyMaker에 의해 생성된 API Gateway 서비스와 스테이지를 API Gateway 서비스 콘솔에서 직접 변경 작업을 할 경우 다음의 주의 사항을 반드시 참고해 주세요. 1. AI EasyMaker가 생성한 API Gateway 서비스와 스테이지를 삭제하지 않도록 합니다. 삭제하면 엔드포인트에 API Gateway 정보가 정상적으로 표시되지 않고, 엔드포인트의 변경 사항이 API Gateway에 적용되지 않을 수 있습니다. 2. 엔드포인트 생성 시 입력한 API Gateway 리소스 경로의 리소스를 변경하거나 삭제하지 않도록 합니다. 삭제하면 엔드포인트의 추론 API 호출에 실패할 수 있습니다. 3. 엔드포인트 생성 시 입력한 API Gateway 리소스 경로 하위에 리소스를 추가하지 않도록 합니다. 추가한 리소스는 엔드포인트 스테이지 추가/변경 작업 시 삭제될 수 있습니다. 4. API Gateway의 스테이지 설정에서 API Gateway 리소스 경로에 설정된 백엔드 엔드포인트 URL 재정의를 비활성화하거나 URL을 변경하지 않도록 합니다. 변경하면 엔드포인트의 추론 API 호출에 실패할 수 있습니다. 위의 주의 사항 외 다른 설정은 필요에 따라 API Gateway에서 제공하는 기능을 이용할 수 있습니다. 자세한 API Gateway 사용에 대한 내용은 API Gateway 콘솔 가이드를 참고해 주세요.
[참고] 스테이지의 API Gateway '배포 실패' 상태인 경우 복구 방법 일시적인 문제로 AI EasyMaker 엔드포인트의 스테이지 설정이 API Gateway 스테이지에 배포되지 않은 경우, 배포 실패 상태로 표시됩니다. 이 경우, 스테이지 목록에서 스테이지 선택 > 하단 상세 화면의 API Gateway 설정 보기 > '스테이지 배포'를 클릭하여 API Gateway 스테이지를 수동으로 배포할 수 있습니다. 위 가이드로도 배포 상태가 복구되지 않는 경우 고객 센터로 문의해 주세요.
스테이지 리소스 생성
기존 엔드포인트 스테이지에 신규 리소스를 추가합니다.
- 모델: 엔드포인트에 배포하려는 모델을 선택합니다. 모델을 생성하지 않은 경우 모델을 먼저 생성하시기 바랍니다.
- API Gateway 리소스 경로: 배포되는 모델의 API 리소스 경로를 입력합니다. 예를 들어
/inference로 설정한 경우POST https://{enpdoint-domain}/inference로 추론 API를 요청할 수 있습니다. - 파드 수: 스테이지 리소스의 파드 수를 입력합니다.
- 설명: 스테이지 리소스 설명을 입력합니다.
스테이지 리소스 목록
엔드포인트 스테이지 하위에 생성된 리소스 목록이 표시됩니다.
-
상태: 스테이지 리소스의 상태가 표시됩니다. 주요 상태는 아래 표를 참고해 주세요.
상태 설명 CREATE REQUESTED 스테이지 리소스 생성이 요청된 상태입니다. CREATE IN PROGRESS 스테이지 리소스를 생성 중인 상태입니다. DELETE IN PROGRESS 스테이지 리소스를 삭제 중인 상태입니다. ACTIVE 스테이지 리소스가 정상적으로 배포된 상태입니다. CREATE FAILED 스테이지 리소스 생성에 실패한 상태입니다. 다시 시도해 주세요. -
모델 이름: 스테이지에 배포된 모델의 이름입니다.
- API Gateway 리소스 경로: 스테이지에 배포된 모델의 엔드포인트 URL입니다. API 클라이언트는 표시된 URL로 API를 요청할 수 있습니다.
- 파드 수: 리소스에서 사용 중인 정상 파드와 전체 파드 수가 표시됩니다.
엔드포인트 추론 호출
- 엔드포인트 > 엔드포인트 스테이지에서 스테이지를 클릭하면 하단에 스테이지 상세 화면이 표시됩니다.
- 상세화면의 스테이지 리소스 탭에서 API Gateway 리소스 경로를 확인합니다.
- HTTP POST Method로 API Gateway 리소스 경로를 호출하면 추론 API가 호출됩니다.
- 사용자가 작성한 알고리즘에 따라 추론 API의 요청, 응답 사양은 다릅니다.
// 추론 API 예시: 요청 curl --location --request POST '{API Gateway 리소스 경로}' \ --header 'Content-Type: application/json' \ --data-raw '{ "instances": [ [6.8, 2.8, 4.8, 1.4], [6.0, 3.4, 4.5, 1.6] ] }' // 추론 API 예시: 응답 { "predictions" : [ [ 0.337502569, 0.332836747, 0.329660654 ], [ 0.337530434, 0.332806051, 0.329663515 ] ] }
스테이지 리소스 삭제
- 엔드포인트 목록에서 엔드포인트 이름을 클릭하여 엔드포인트 스테이지 목록으로 이동합니다.
- 엔드포인트 스테이지 목록에서 삭제할 스테이지 리소스가 배포된 엔드포인트 스테이지를 클릭합니다. 클릭하면 하단에 스테이지 상세 화면이 표시됩니다.
- 상세 화면의 스테이지 리소스 탭에서 삭제할 스테이지 리소스를 선택합니다.
- 스테이지 리소스 삭제를 클릭합니다.
- 요청된 삭제 작업은 취소할 수 없습니다. 계속 진행하려면 확인을 클릭합니다.
엔드포인트 기본 스테이지 변경
엔드포인트의 기본 스테이지를 다른 스테이지로 변경합니다. 서비스의 순단 없이 엔드포인트의 모델을 변경하려면 AI EasyMaker는 스테이지 기능을 활용하여 모델을 배포하는 것을 권장합니다.
- 실제 서비스로 운영 중인 스테이지는 기본 스테이지에서 운영합니다.
- 신규 모델로 교체하는 경우, 기존 엔드포인트에 신규 스테이지를 추가합니다.
- 신규 스테이지에서 교체된 모델로 엔드포인트 서비스에 문제가 없는지 확인합니다.
- 기본 스테이지 변경을 클릭합니다.
- 기본 스테이지로 변경하는 신규 스테이지를, 변경할 스테이지에서 선택합니다.
- 변경 요청 작업은 취소할 수 없습니다. 계속 진행하려면 확인을 클릭합니다.
- 변경할 스테이지가 기본 스테이지로 변경되며, 기존 기본 스테이지의 리소스는 자동으로 삭제됩니다.
엔드포인트 스테이지 삭제
- 엔드포인트 목록에서 엔드포인트 이름을 클릭하여 엔드포인트 스테이지 목록으로 이동합니다.
- 엔드포인트 스테이지 목록에서 삭제할 엔드포인트 스테이지를 선택합니다. 기본 스테이지는 삭제할 수 없습니다.
- 스테이지 삭제를 클릭합니다.
- 요청된 삭제 작업은 취소할 수 없습니다. 계속 진행하려면 확인을 클릭합니다.
[주의] 엔드포인트 스테이지 삭제 시 API Gateway 서비스의 스테이지 삭제 AI EasyMaker의 엔드포인트 스테이지를 삭제하면, 엔드포인트의 스테이지가 배포된 API Gateway 서비스의 스테이지도 삭제됩니다. 삭제되는 API Gateway 스테이지에 운영 중인 API가 존재하는 경우, API 호출이 불가하므로 주의해 주세요.
엔드포인트 삭제
엔드포인트를 삭제합니다.
- 엔드포인트 목록에서 삭제하려는 엔드포인트를 선택합니다.
- 엔드포인트 하위에 기본 스테이지를 제외한 스테이지가 존재하는 경우, 엔드포인트를 삭제할 수 없습니다. 먼저 다른 스테이지를 삭제한 후 엔드포인트를 삭제해 주세요.
- 엔드포인트 삭제를 클릭합니다.
- 요청된 삭제 작업은 취소할 수 없습니다. 계속 진행하려면 확인을 클릭합니다.
[주의] 엔드포인트 삭제 시 API Gateway 서비스 삭제 AI EasyMaker의 엔드포인트를 삭제하면, 엔드포인트가 배포된 API Gateway 서비스도 삭제됩니다. 삭제되는 API Gateway 서비스에 운영 중인 API가 존재하는 경우, API 호출이 불가하므로 주의해 주세요.
배치 추론
AI EasyMaker의 모델로 배치 추론하고 추론 결과를 통계로 확인할 수 있는 환경을 제공합니다.
배치 추론 생성
인스턴스와 OS 이미지를 선택하여 배치 추론이 수행될 환경을 설정하고, 추론할 입력/출력 데이터의 경로를 입력하여 배치 추론을 진행합니다.
- 기본 정보: 배치 추론에 대한 기본 정보를 입력합니다.
- 배치 추론 이름: 배치 추론 이름을 입력합니다.
- 배치 추론 설명: 설명을 입력합니다.
- 인스턴스 정보
- 인스턴스 타입: 배치 추론을 실행할 인스턴스 타입을 선택합니다.
- 인스턴스 수: 배치 추론을 수행할 인스턴스 수입니다.
- 모델 정보
- 모델: 배치 추론할 모델을 선택합니다. 모델을 생성하지 않은 경우 모델을 먼저 생성하시기 바랍니다.
- 파드 수: 모델의 파드 수를 입력합니다.
- 리소스 정보: 모델에서 실제 사용하는 리소스를 확인할 수 있습니다. 입력한 파드 수에 따라 실사용량을 분할하여 각 파드에 할당됩니다.
- 입력 데이터
- 데이터 경로: 배치 추론을 실행할 데이터의 경로를 입력합니다.
- NHN Cloud Object Storage 또는 NHN Cloud NAS 경로를 입력합니다.
- 입력 데이터 구분: 배치 추론을 실행할 데이터의 유형을 선택합니다.
- JSON: 파일의 유효한 JSON 데이터를 입력 값으로 사용합니다.
- JSONL: 각 줄이 유효한 JSON으로 이뤄진 JSON Lines 파일들을 입력 값으로 사용합니다.
- Glob 패턴
- 포함 파일 지정: 입력 데이터에 포함할 파일 집합을 Glob 패턴으로 입력합니다.
- 제외 파일 지정: 입력 데이터에서 제외할 파일 집합을 Glob 패턴으로 입력합니다.
- 데이터 경로: 배치 추론을 실행할 데이터의 경로를 입력합니다.
- 출력 데이터
- 출력 데이터: 배치 추론의 실행 결과를 저장할 데이터 저장 경로를 입력합니다.
- NHN Cloud Object Storage 또는 NHN Cloud NAS 경로를 입력합니다.
- 출력 데이터: 배치 추론의 실행 결과를 저장할 데이터 저장 경로를 입력합니다.
- 추가 설정
- 배치 옵션
- 배치 크기: 한 번의 추론 작업에서 동시에 처리되는 데이터 샘플의 수를 입력합니다.
- 추론 제한 시간(초): 배치 추론의 제한 시간을 입력합니다. 단일 추론 요청이 처리되고 결과가 반환되기까지의 최대 허용 시간을 설정할 수 있습니다.
- 데이터 스토리지 크기: 배치 추론을 실행할 인스턴스의 데이터 스토리지 크기를 입력합니다.
- NHN Cloud Object Storage를 사용하는 경우에만 사용됩니다. 배치 추론에 필요한 데이터가 모두 저장될 수 있도록 충분한 크기를 지정하시기 바랍니다.
- 최대 배치 추론 시간: 배치 추론이 완료될 때까지 최대 대기 시간을 지정합니다. 최대 대기 시간이 초과한 배치 추론은 종료 처리됩니다.
- 로그 관리: 배치 추론 진행 중 발생하는 로그를 NHN Cloud Log \& Crash Search 서비스에 저장할 수 있습니다.
- 자세한 내용은 부록 > 2. NHN Cloud Log & Crash Search 서비스 이용 안내 및 로그 확인을 참고해 주세요.
- 태그: 태그를 추가하려면 + 버튼을 클릭하여 Key-Value 형식으로 태그를 입력합니다. 태그는 최대 10개까지 입력할 수 있습니다.
- 배치 옵션
[주의] NHN Cloud NAS를 사용하는 경우 AI EasyMaker와 동일한 프로젝트에서 생성된 NHN Cloud NAS만 사용 가능합니다.
[주의] 배치 추론 입력 데이터 삭제 시 배치 추론 실패 배치 추론이 완료되기 전 입력 데이터를 삭제하면 배치 추론에 실패할 수 있습니다.
[주의] 입력 데이터 상세 옵션을 설정하는 경우 Glob 패턴을 적절하게 입력하지 않았을 경우, 입력 데이터를 찾을 수 없어 배치 추론이 정상적으로 동작하지 않을 수 있습니다. 포함 Glob 패턴과 같이 사용할 경우 제외 Glob 패턴이 우선하여 적용됩니다
[주의] 배치 옵션을 설정하는 경우 배치 추론하는 모델의 성능에 따라 배치 크기와 추론 제한 시간을 적절히 설정해야 합니다. 입력한 설정값이 올바르지 않은 경우 배치 추론이 충분한 성능을 내지 못할 수 있습니다.
배치 추론 목록
배치 추론 목록이 표시됩니다. 목록의 배치 추론을 선택하면 상세 정보를 확인하고 정보를 변경할 수 있습니다.
- 추론 소요 시간: 배치 추론이 진행된 시간이 표시됩니다.
-
상태: 배치 추론의 상태가 표시됩니다. 주요 상태는 아래 표를 참고해 주세요.
상태 설명 CREATE REQUESTED 배치 추론 생성을 요청한 상태입니다. CREATE IN PROGRESS 배치 추론에 필요한 자원을 생성 중인 상태입니다. RUNNING 배치 추론이 진행 중인 상태입니다. STOPPED 배치 추론이 사용자의 요청으로 중지된 상태입니다. COMPLETE 배치 추론이 정상적으로 완료된 상태입니다. STOP IN PROGRESS 배치 추론이 중지 중인 상태입니다. FAIL BATCH INFERENCE 배치 추론 진행 중 실패한 상태입니다. 자세한 실패 정보는 로그 관리가 활성화된 경우, Log \& Crash Search 로그를 통해 확인할 수 있습니다. CREATE FAILED 배치 추론 생성을 실패한 상태입니다. 생성이 지속적으로 실패하면 고객 센터로 문의해 주세요. FAIL BATCH INFERENCE IN PROGRESS, COMPLETE IN PROGRESS 배치 추론에 사용된 리소스를 정리 중인 상태입니다. * 작업 * 중지: 진행 중인 배치 추론을 중지할 수 있습니다. * 모니터링: 배치 추론을 선택하면 표시되는 상세 화면의 모니터링 탭에서 모니터링 대상 인스턴스 목록과 기본 지표 차트를 확인할 수 있습니다. * 모니터링 탭은 배치 추론이 생성 중인 상태에는 비활성화됩니다.
배치 추론 복사
기존 배치 추론과 동일한 설정으로 새로운 배치 추론을 생성합니다.
- 복사하려는 배치 추론을 선택합니다.
- 배치 추론 복사를 클릭합니다.
- 기존 배치 추론과 동일한 설정으로 배치 추론 생성 화면이 표시됩니다.
- 설정을 변경하려는 정보가 있다면 변경한 후 배치 추론 생성을 클릭하여 배치 추론을 생성합니다.
배치 추론 삭제
배치 추론을 삭제합니다.
- 삭제하려는 배치 추론을 선택합니다.
- 배치 추론 삭제를 클릭합니다. 진행 중인 배치 추론은 중지 후 삭제할 수 있습니다.
- 요청된 삭제 작업은 취소할 수 없습니다. 계속 진행하려면 확인을 클릭합니다.
개인 이미지
사용자가 개인화한 컨테이너 이미지를 이용하여 노트북, 학습, 하이퍼파라미터 튜닝을 구동할 수 있습니다. AI EasyMaker에서 제공하는 노트북/딥 러닝 이미지를 기반으로 파생된 개인 이미지만 AI EasyMaker에서 리소스 생성 시 이용할 수 있습니다. AI EasyMaker의 기반 이미지는 아래 표를 확인해 주세요.
노트북 이미지
| 이미지 이름 | 코어타입 | 프레임워크 | 프레임워크 버전 | 파이썬 버전 | 이미지 주소 |
|---|---|---|---|---|---|
| Ubuntu 22.04 CPU Python Notebook | CPU | Python | 3.10.12 | 3.10 | fb34a0a4-kr1-registry.container.nhncloud.com/easymaker/python-notebook:3.10.12-cpu-py310-ubuntu2204 |
| Ubuntu 22.04 GPU Python Notebook | GPU | Python | 3.10.12 | 3.10 | fb34a0a4-kr1-registry.container.nhncloud.com/easymaker/python-notebook:3.10.12-gpu-py310-ubuntu2204 |
| Ubuntu 22.04 CPU PyTorch Notebook | CPU | PyTorch | 2.0.1 | 3.10 | fb34a0a4-kr1-registry.container.nhncloud.com/easymaker/pytorch-notebook:2.0.1-cpu-py310-ubuntu2204 |
| Ubuntu 22.04 GPU PyTorch Notebook | GPU | PyTorch | 2.0.1 | 3.10 | fb34a0a4-kr1-registry.container.nhncloud.com/easymaker/pytorch-notebook:2.0.1-gpu-py310-ubuntu2204 |
| Ubuntu 22.04 CPU TensorFlow Notebook | CPU | TensorFlow | 2.12.0 | 3.10 | fb34a0a4-kr1-registry.container.nhncloud.com/easymaker/tensorflow-notebook:2.12.0-cpu-py310-ubuntu2204 |
| Ubuntu 22.04 GPU TensorFlow Notebook | GPU | TensorFlow | 2.12.0 | 3.10 | fb34a0a4-kr1-registry.container.nhncloud.com/easymaker/tensorflow-notebook:2.12.0-gpu-py310-ubuntu2204 |
딥 러닝 이미지
| 이미지 이름 | 코어타입 | 프레임워크 | 프레임워크 버전 | 파이썬 버전 | 이미지 주소 |
|---|---|---|---|---|---|
| Ubuntu 22.04 CPU PyTorch Training | CPU | PyTorch | 2.0.1 | 3.10 | fb34a0a4-kr1-registry.container.nhncloud.com/easymaker/pytorch-train:2.0.1-cpu-py310-ubuntu2204 |
| Ubuntu 22.04 GPU PyTorch Training | GPU | PyTorch | 2.0.1 | 3.10 | fb34a0a4-kr1-registry.container.nhncloud.com/easymaker/pytorch-train:2.0.1-gpu-py310-ubuntu2204 |
| Ubuntu 22.04 CPU TensorFlow Training | CPU | TensorFlow | 2.12.0 | 3.10 | fb34a0a4-kr1-registry.container.nhncloud.com/easymaker/tensorflow-train:2.12.0-cpu-py310-ubuntu2204 |
| Ubuntu 22.04 GPU TensorFlow Training | GPU | TensorFlow | 2.12.0 | 3.10 | fb34a0a4-kr1-registry.container.nhncloud.com/easymaker/tensorflow-train:2.12.0-gpu-py310-ubuntu2204 |
[참고] 개인 이미지 사용 제약 사항 * AI EasyMaker에서 제공하는 기반 이미지로 파생된 개인 이미지만 사용할 수 있습니다. * 개인 이미지가 저장되는 컨테이너 레지스트리 서비스로는 NHN Container Registry(NCR)만 연동 가능합니다. (2023년 12월 기준)
개인 이미지 생성
다음 문서는 도커(Docker)를 활용하여 AI EasyMaker 기반 이미지로 컨테이너 이미지를 생성하고, AI EasyMaker에서 노트북용 개인 이미지를 사용하는 방법을 안내합니다.
-
개인 이미지의 DockerFile을 작성합니다.
FROM fb34a0a4-kr1-registry.container.nhncloud.com/easymaker/python-notebook:3.10.12-cpu-py310-ubuntu2204 as easymaker-notebook RUN conda create -n example python=3.10 RUN conda activate example RUN pip install torch torchvision -
개인 이미지 빌드와 컨테이너 레지스트리 Push Dockerfile로 이미지를 빌드하고 NCR 레지스트리에 이미지를 저장(Push)합니다.
docker build -t {이미지 이름}:{태그} . docker tag {이미지 이름}:{태그} {NCR 레지스트리 주소}/{이미지 이름}:{태그} docker push {NCR 레지스트리 주소}/{이미지 이름}:{태그} (예시) docker build -t custom-training:v1 . docker tag custom-training:v1 example-kr1-registry.container.nhncloud.com/registry/custom-training:v1 docker push example-kr1-registry.container.nhncloud.com/registry/custom-training:v1 -
NCR에 저장(Push)한 이미지를 AI EasyMaker의 개인 이미지로 생성합니다.
- AI EasyMaker 콘솔의 이미지 메뉴로 이동합니다.
- 이미지 생성 버튼을 클릭하여, 생성한 이미지의 정보를 입력합니다.
- 이름, 설명: 이미지에 대한 이름과 설명을 입력합니다.
- 주소: 레지스트리 이미지 주소를 입력합니다.
- 타입: 컨테이너 이미지의 타입을 입력합니다. 노트북 또는 학습을 선택합니다.
- 계정: AI EasyMaker 노트북/학습 노드가 사용자의 레지스트리 저장소에 접근하기 위한 계정을 선택합니다.
- 신규 사용: 신규 레지스트리 계정을 등록합니다.
- 이름, 설명: 레지스트리 계정에 대한 이름과 설명을 입력합니다.
- 분류: 컨테이너 레지스트리 서비스를 선택합니다.
- 아이디: 레지스트리 저장소의 아이디를 입력합니다.
- 비밀번호: 레지스트리 저장소의 비밀번호를 입력합니다.
- 기존 계정 사용: 이미 등록된 레지스트리 계정을 선택합니다.
- 신규 사용: 신규 레지스트리 계정을 등록합니다.
-
생성한 개인 이미지로 노트북을 생성합니다.
- 노트북 메뉴로 이동합니다. 노트북 생성 버튼을 클릭하여 노트북 생성 페이지로 이동합니다.
- 이미지 정보에서 개인 이미지 탭을 클릭합니다.
- 노트북 컨테이너 이미지로 사용할 개인 이미지를 선택합니다.
- 기타 노트북 정보를 입력한 후 생성하면, 개인 이미지로 노트북이 구동됩니다.
[참고] 노트북 이외 학습, 하이퍼파라미터 튜닝도 동일하게 개인 이미지를 사용하여 리소스를 생성할 수 있습니다.
[참고] 컨테이너 레지스트리 서비스: NHN Container Registry(NCR) 컨테이너 레지스트 서비스로 NCR 서비스만 연동 가능합니다. (2023년 12월 기준)
NCR 서비스의 계정 아이디와 비밀번호는 다음의 값을 입력합니다.
아이디: NHN Cloud 사용자 계정의 User Access Key
비밀번호: NHN Cloud 사용자 계정의 User Secret Key
레지스트리 계정
AI EasyMaker가 개인 이미지가 저장된 사용자의 레지스트리에서 이미지를 가져와서(Pull) 컨테이너를 구동하려면 사용자의 레지스트리에 로그인해야 합니다. 레지스트리 계정으로 로그인 정보를 저장해 두면 해당 레지스트리 계정으로 연동된 이미지에서 재사용할 수 있습니다. 레지스트리 계정을 관리하려면 AI EasyMaker 콘솔의 이미지 메뉴로 이동한 후, 레지스트리 계정 탭을 선택합니다.
레지스트리 계정 생성
신규 레지스트리 계정을 생성합니다.
- 이름: 레지스트리 계정의 이름을 입력합니다.
- 설명: 레지스트리 계정의 설명을 입력합니다.
- 분류: 컨테이너 레지스트리 서비스를 선택합니다.
- 아이디: 레지스트리 계정의 아이디를 입력합니다.
- 비밀번호: 레지스트리 계정의 비밀번호를 입력합니다.
레지스트리 계정 수정
레지스트리 아이디, 비밀번호 수정
- 레지스트리 계정 수정 버튼을 클릭합니다.
- 아이디와 비밀번호를 새로 입력한 후 확인 버튼을 클릭합니다.
[참고] 레지스트리 계정을 변경하면 해당 계정과 연동된 이미지를 사용할 때 변경된 아이디와 비밀번호로 레지스트리 서비스에 로그인합니다. 잘못된 레지스트리 아이디, 비밀번호를 입력하면 개인 이미지 Pull 진행 중 로그인에 실패하여 리소스 생성을 실패합니다. 레지스트리 계정이 연동된 개인 이미지로 생성 중인 리소스가 있거나 수행 중인 학습 및 하이퍼파라미터가 있을 경우에는 수정할 수 없습니다.
레지스트리 계정 > 이름, 설명 변경
- 레지스트리 계정 목록에서 변경할 계정을 선택합니다.
- 하단 화면의 변경 버튼을 클릭합니다.
- 이름과 설명을 변경한 후 확인 버튼을 클릭합니다.
레지스트리 계정 삭제
삭제할 레지스트리 계정을 목록에서 선택하고, 레지스트리 계정 삭제 버튼을 클릭합니다.
[참고] 이미지와 연동된 레지스트리 계정은 삭제할 수 없습니다. 삭제하려면 연동된 이미지를 먼저 삭제한 뒤 레지스트리 계정을 삭제해야 합니다.
부록
1. NHN Cloud Object Storage에 AI EasyMaker 시스템 계정 권한 추가
AI EasyMaker의 일부 기능에서 입출력 스토리지로 사용자의 NHN Cloud Object Storage를 사용하는 경우, 사용자의 NHN Cloud Object Stroage 컨테이너에 AI EasyMaker 시스템 계정에 대한 읽기 또는 쓰기 권한을 허용해야 정상적인 기능 동작이 됩니다.
사용자의 NHN Cloud Object Stroage 컨테이너에 AI EasyMaker 시스템 계정의 읽기/쓰기 권한을 허용하는 것은 AI EasyMaker 시스템 계정이 사용자의 NHN Cloud Object Stroage 컨테이너의 모든 파일에 대해 부여된 권한에 따라 파일을 읽거나 쓸수 있음을 의미합니다.
이 내용을 반드시 확인하여 필요한 계정과 권한만 사용자 Object Storage에 접근 정책을 설정해야 합니다.
접근 정책 설정 과정 중 AI EasyMaker 시스템 계정이 아닌 다른 계정에 대해 사용자의 Object Storage 접근을 허용하여 발생한 모든 결과에 대한 책임은 '사용자'에게 있으며 AI EasyMaker는 그에 대해 책임을 지지 않습니다.
[참고] 기능에 따라 AI EasyMaker가 Object Stroage에 접근하여 읽거나 쓰는 파일은 다음과 같습니다.
| 기능 | 권한 | 접근 대상 |
|---|---|---|
| 학습 | 읽기 | 사용자가 입력한 알고리즘 경로, 학습 입력 데이터 경로 |
| 학습 | 쓰기 | 사용자가 입력한 학습 출력 데이터, 체크 포인트 경로 |
| 모델 | 읽기 | 사용자가 입력한 모델 아티팩트 경로 |
| 엔드포인트 | 읽기 | 사용자가 입력한 모델 아티팩트 경로 |
NHN Cloud Object Storage에 AI EasyMaker 시스템 계정의 읽기/쓰기 권한을 추가하려면 다음 내용을 참고해 주세요.
- [학습] 또는 [모델] 탭 > AI EasyMaker 시스템 계정 정보를 클릭합니다.
- AI EasyMaker 시스템 계정 정보인 AI EasyMaker 테넌트 ID와 AI EasyMaker API 사용자 ID를 보관합니다.
- NHN Cloud Object Storage 콘솔로 이동합니다.
- 특정 프로젝트 또는 특정 사용자에게 읽기/쓰기 허용 문서를 참고하여 NHN Cloud Object Storage 콘솔에서 AI EasyMaker 시스템 계정에 필요한 읽기 및 쓰기 허용 권한을 추가합니다.
2. NHN Cloud Log & Crash Search 서비스 이용 안내 및 로그 조회 방법
NHN Cloud Log & Crash Search 서비스 이용 안내
AI EasyMaker 서비스에서 발생하는 로그, 이벤트를 NHN Cloud Log & Crash Search 서비스에 저장할 수 있습니다. Log & Crash Search 서비스에 로그를 저장하려면, Log & Crash 서비스를 활성화해야 하며 별도 이용 요금이 부과됩니다.
- Log & Crash Search 서비스 이용 및 요금 안내
- Log & Crash Search 서비스에 대한 자세한 내용과 요금은 다음의 문서를 확인하시기 바랍니다.
로그 조회
- Log & Crash Search 서비스 콘솔 페이지로 이동합니다.
- Log & Crash Search 서비스에서 검색 조건을 입력하여 로그들을 조회합니다.
- AI EasyMaker 학습 로그 질의: category 필드가 "easymaker.training"인 로그를 조회합니다.
- 질의문: category:"easymaker.training"
- AI EasyMaker 엔드포인트 로그 질의: category 필드가 "easymaker.inference"인 로그를 조회합니다.
- 질의문: category:"easymaker.inference"
- AI EasyMaker 로그 전체 조회 질의: logType 필드가 "NNHCloud-AIEasyMaker"인 로그를 조회합니다.
- 질의문: logType:"NHNCloud-AIEasyMaker"
- AI EasyMaker 학습 로그 질의: category 필드가 "easymaker.training"인 로그를 조회합니다.
- Log & Crash Search 서비스의 자세한 이용 방법은 Log & Crash Search 서비스의 콘솔 가이드를 참고해 주세요.
AI EasyMaker 서비스는 Log & Crash Search 서비스에 다음과 같이 정의된 필드로 로그를 전송합니다.
-
공통 로그 필드
이름 설명 유효 범위 easymakerAppKey AI EasyMaker 앱키(AppKey) - category 로그 카테고리 easymaker.training, easymaker.inference logLevel 로그 레벨 INFO, WARNING, ERROR body 로그 내용 - logType 로그 제공 서비스 이름 NHNCloud-AIEasyMaker time 로그 발생 시간(UTC 시각) - -
학습 로그 필드
이름 설명 trainingId AI EasyMaker 학습 ID -
하이퍼파라미터 튜닝 로그 필드
이름 설명 hyperparameterTuningId AI EasyMaker 하이퍼파라미터 튜닝 ID -
엔드포인트 로그 필드
이름 설명 endpointId AI EasyMaker 엔드포인트 ID endpointStageId 엔드포인트 스테이지 ID inferenceId 추론 요청 고유 ID action Action 구분(Endpoint.Model) modelName 추론 대상 모델 이름 -
배치 추론 로그 필드
이름 설명 batchInferenceId AI EasyMaker 배치 추론 ID
3. 하이퍼파라미터
- 콘솔을 통해 입력 받은 Key-Value 형식의 값입니다.
- 엔트리 포인트 실행 시, 실행 인자(--{Key})로 전달됩니다.
- 환경 변수 값(EM_HP_{대문자로 변환된 Key})으로도 저장되어 활용할 수 있습니다.
아래 예시처럼, 학습 생성 시 입력한 하이퍼파라미터 값을 활용할 수 있습니다.
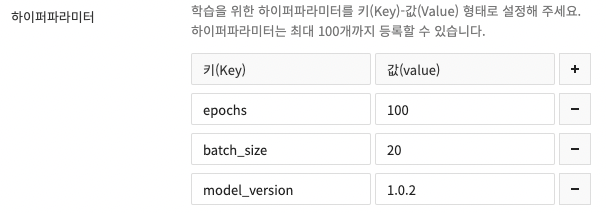
import argparse
model_version = os.environ.get("EM_HP_MODEL_VERSION")
def parse_hyperparameters():
parser = argparse.ArgumentParser()
# 입력한 하이퍼파라미터 파싱
parser.add_argument("--epochs", type=int, default=500)
parser.add_argument("--batch_size", type=int, default=32)
...
return parser.parse_known_args()
4. 환경 변수
- 학습에 필요한 정보들은 환경 변수로 학습 컨테이너에 전달되며, 학습 스크립트에서 전달된 환경 변수들을 활용할 수 있습니다.
- 사용자 입력으로 만들어지는 환경 변수명은 대문자로 변환됩니다.
- 코드 상에서 학습이 완료된 모델은 반드시 EM_MODEL_DIR 경로에 저장해야 합니다.
-
주요 환경 변수
환경 변수명 설명 EM_SOURCE_DIR 학습 생성 시 입력한 알고리즘 스크립트가 다운로드되어 있는 폴더의 절대 경로 EM_ENTRY_POINT 학습 생성 시 입력한 알고리즘 엔트리 포인트 이름 EM_DATASET_${데이터 세트 이름} 학습 생성 시 입력한 각각의 데이터 세트가 다운로드되어 있는 폴더의 절대 경로 EM_DATASETS 전체 데이터 세트 목록(json 형식) EM_MODEL_DIR 모델 저장 경로 EM_CHECKPOINT_INPUT_DIR 입력 체크 포인트 저장 경로 EM_CHECKPOINT_DIR 출력 체크 포인트 저장 경로 EM_HP_${대문자로 변환된 하이퍼파라미터 키} 하이퍼파라미터 키에 대응하는 하이퍼파라미터 값 EM_HPS 전체 하이퍼파라미터 목록(json 형식) EM_TENSORBOARD_LOG_DIR 학습 결과 확인을 위한 텐서보드 로그 경로 EM_REGION 현재 리전 정보 EM_APPKEY 현재 사용 중인 AI EasyMaker 서비스의 앱키 -
환경 변수 활용 예시 코드
import os import tensorflow dataset_dir = os.environ.get("EM_DATASET_TRAIN") train_data = read_data(dataset_dir, "train.csv") model = ... # 입력한 데이터를 이용해 모델 구현 model.load_weights(os.environ.get('EM_CHECKPOINT_INPUT_DIR', None)) callbacks = [ tensorflow.keras.callbacks.ModelCheckpoint(filepath=f'{os.environ.get("EM_CHECKPOINT_DIR")}/cp-{{epoch:04d}}.ckpt', save_freq='epoch', period=50), tensorflow.keras.callbacks.TensorBoard(log_dir=f'{os.environ.get("EM_TENSORBOARD_LOG_DIR")}'), ] model.fit(..., callbacks) model_dir = os.environ.get("EM_MODEL_DIR") model.save(model_dir)
5. 텐서보드 활용을 위한 지표 로그 저장
-
학습 후 텐서보드 화면에서 결과 지표를 확인하기 위해, 학습 스크립트 작성 시 텐서보드 로그 저장 공간을 지정된 위치(
EM_TENSORBOARD_LOG_DIR)로 설정해 주어야 합니다. -
텐서보드 로그 저장 예시 코드(TensorFlow)
import tensorflow as tf # 텐서보드 로그 경로 지정 tb_log = tf.keras.callbacks.TensorBoard(log_dir=os.environ.get("EM_TENSORBOARD_LOG_DIR")) model = ... # 모델 구현 model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=100, batch_size=20, callbacks=[tb_log])
6. 프레임워크별 분산 학습 설정
- Tensorflow
- 분산 학습에 필요한 환경 변수
TF_CONFIG는 자동으로 설정됩니다. 자세한 내용은 Tensorflow 공식 가이드 문서를 참고해 주세요.
- 분산 학습에 필요한 환경 변수
- Pytorch
- 분산 학습을 하기 위해서
Backends설정이 필요합니다. 분산 학습을 CPU로 진행할 경우 gloo로, GPU로 진행할 경우 nccl로 설정해 주세요. 자세한 내용은 Pytorch 공식 가이드 문서를 참고해 주세요.
- 분산 학습을 하기 위해서
7. 클러스터 버전 업그레이드
AI EasyMaker 서비스는 안정적인 서비스와 신규 기능 제공을 위해 주기적으로 클러스터 버전을 업그레이드합니다. 신규 클러스터 버전이 배포되면 구 버전의 클러스터에 구동된 노트북 및 엔드포인트를 신규 클러스터로 이전해야 합니다. 리소스별 신규 클러스터 이전 방법을 안내합니다.
노트북 클러스터 버전 업그레이드
노트북 목록 화면에서 신규 클러스터로 이전해야 하는 노트북은 이름 좌측에 재시작 버튼이 표시됩니다. 재시작 버튼 위에 마우스 포인터를 올리면 재시작 안내 문구와 만료 일시가 표시됩니다.
- 만료 전 다음의 주의 사항을 반드시 확인한 뒤 재시작 버튼을 클릭합니다.
- 재시작 시 데이터 스토리지(/root/easymaker 디렉터리 경로)에 저장된 데이터는 그대로 유지됩니다.
- 재시작을 실행하면 부트 스토리지에 저장된 데이터는 초기화되어 유실될 수 있습니다. 데이터를 데이터 스토리지로 이동한 뒤 재시작해 주세요.
재시작은 최초 실행 시 약 25분이 소요되며, 이후에는 약 10분이 소요됩니다. 재시작을 실패할 경우 관리자에게 자동으로 보고됩니다.
엔드포인트 클러스터 버전 업그레이드
엔드포인트 목록 화면에서 신규 클러스터로 이전해야 하는 엔드포인트는 이름 좌측에 ! 안내 문구가 표시됩니다. ! 안내 문구 위에 마우스 포인터를 올리면 버전 업그레이드 안내 문구와 만료 일시가 표시됩니다. 만료 전까지 다음의 안내에 따라 구 버전 클러스터에서 운영되는 스테이지를 신규 버전 클러스터로 이전해야 합니다.
일반 스테이지의 클러스터 버전 업그레이드
- 기본 스테이지가 아닌 일반 스테이지는 삭제합니다. 삭제 전 해당 스테이지가 서비스 중인지 먼저 확인합니다.
- 스테이지를 다시 생성합니다.
- 신규 스테이지가 ACTIVE 상태가 되면 스테이지 엔트포인트로 API 호출과 추론 응답이 정상적으로 오는지 확인합니다.
[주의] 스테이지를 삭제하면 엔드포인트가 종료되어 API 호출이 불가합니다. 삭제 전 서비스 중이지 않은 스테이지인지 확인합니다.
기본 스테이지의 클러스터 버전 업그레이드
기본 스테이지는 실제 서비스가 운영되는 스테이지입니다. 서비스의 순단 없이 기본 스테이지의 클러스터 버전을 이전하려면 다음의 가이드에 따라 이전합니다.
- 구 버전 클러스터의 기본 스테이지를 대체할 신규 스테이지를 생성합니다.
- 신규 스테이지 엔드포인트에서 정상적으로 API 호출과 추론 응답이 오는지 확인합니다.
- 기본 스테이지 변경 버튼을 클릭합니다. 신규 스테이지를 선택하여 기본 스테이지로 변경합니다.
- 변경이 완료되면 신규 스테이지가 기본 스테이지로 설정되며, 기존의 기본 스테이지는 삭제됩니다.
8. torchrun 사용 방법
- Pytorch에서 분산 학습이 가능하도록 코드를 작성하였고, 분산 노드 수와 노드당 프로세스 개수를 입력하면 torchrun을 이용한 분산 노드 및 멀티 프로세스를 활용한 분산 학습이 이루어집니다.
- 총 프로세스 개수, 모델 크기, 입력 데이터 크기, 배치 사이즈 등의 요소에 의하여 메모리 부족으로 학습 및 하이퍼파라미터 튜닝이 실패할 수 있습니다. 메모리 부족으로 실패하는 경우 아래와 같은 에러 메시지가 남을 수 있습니다. 단, 아래의 메시지가 남는다고 하여 모두 메모리 부족으로 인한 실패는 아닙니다. 메모리 사용량에 따라 적절한 인스턴스 타입을 설정해 주세요.
exit code : -9 (pid: {pid})
- torchrun에 관한 더 자세한 내용은 Pytorch 공식 가이드 문서를 참고해 주세요.
목차
- Machine Learning > AI EasyMaker > 콘솔 사용 가이드
- 대시보드
- 서비스 이용 현황
- 서비스 모니터링
- 리소스 사용률
- 노트북
- 노트북 생성
- 노트북 목록
- 사용자 가상 실행 환경 구성
- 노트북 중지
- 노트북 인스턴스 타입 변경
- 노트북 삭제
- 실험
- 실험 생성
- 실험 목록
- 실험 삭제
- 학습
- 학습 생성
- 학습 목록
- 학습 복사
- 학습에서 모델 생성하기
- 학습 삭제
- 하이퍼파라미터 튜닝
- 하이퍼파라미터 튜닝 생성
- 하이퍼파라미터 튜닝 목록
- 하이퍼파라미터 튜닝의 학습 목록
- 하이퍼파라미터 튜닝 복사
- 하이퍼파라미터 튜닝에서 모델 생성하기
- 하이퍼파라미터 튜닝 삭제
- 학습 템플릿
- 학습 템플릿 생성
- 학습 템플릿 목록
- 학습 템플릿 복사
- 학습 템플릿 삭제
- 모델
- 모델 생성
- 모델 목록
- 모델에서 엔드포인트 생성하기
- 모델 삭제
- 엔드포인트
- 엔드포인트 생성
- 엔드포인트 목록
- 엔드포인트 스테이지 생성
- 엔드포인트 스테이지 목록
- 스테이지 리소스 생성
- 스테이지 리소스 목록
- 엔드포인트 추론 호출
- 스테이지 리소스 삭제
- 엔드포인트 기본 스테이지 변경
- 엔드포인트 스테이지 삭제
- 엔드포인트 삭제
- 배치 추론
- 배치 추론 생성
- 배치 추론 목록
- 배치 추론 복사
- 배치 추론 삭제
- 개인 이미지
- 노트북 이미지
- 딥 러닝 이미지
- 개인 이미지 생성
- 레지스트리 계정
- 레지스트리 계정 생성
- 레지스트리 계정 수정
- 레지스트리 계정 삭제
- 부록
- 1. NHN Cloud Object Storage에 AI EasyMaker 시스템 계정 권한 추가
- 2. NHN Cloud Log & Crash Search 서비스 이용 안내 및 로그 조회 방법
- 3. 하이퍼파라미터
- 4. 환경 변수
- 5. 텐서보드 활용을 위한 지표 로그 저장
- 6. 프레임워크별 분산 학습 설정
- 7. 클러스터 버전 업그레이드
- 8. torchrun 사용 방법