Data & Analytics > DataQuery > 콘솔 사용 가이드
DataQuery 서비스를 사용하려면 반드시 데이터 소스를 추가해야 합니다. 아래와 같은 절차를 통해 서비스를 사용할 수 있습니다.
- 연동할 데이터 소스 추가
- 데이터 소스를 반영하기 위한 클러스터 시작
- 웹 콘솔의 쿼리 편집기 또는 외부 접속 URL을 통한 별도 툴에서의 쿼리 실행
데이터 소스
데이터 소스 추가
- 데이터 소스 설정 및 반영 제약 사항
- Object Storage 유형의 데이터 소스가 반드시 존재해야 다른 데이터 소스를 추가할 수 있습니다.
- Object Storage 유형의 데이터 소스가 반드시 존재해야 클러스터를 활성화하고 쿼리를 실행할 수 있습니다.
- Object Storage 유형의 데이터 소스는 하나만 등록할 수 있습니다.
- 접근 제어가 설정된 데이터 소스 연결 시에는 DataQuery IP 고정 기능을 사용해야 합니다.
- DataQuery IP 고정 기능을 사용하려면 고객 센터로 문의하십시오.
- 데이터 소스 추가를 클릭합니다.
Object Storage 데이터 소스 유형
- 데이터 소스 추가를 클릭한 뒤 데이터 소스 추가 페이지에서 Object Storage 정보를 입력합니다.
- 데이터 소스 이름
- 쿼리 수행 시 사용되는 구분자이며, 데이터 소스 사이에서 고유한 값이어야 합니다.
- 액세스 키, 비밀 키, 리전
- 연동할 데이터가 존재하는 Object Storage의 연결 정보입니다.
- 액세스 키와 비밀 키는 Object Storage 콘솔에서 발급할 수 있습니다. 자세한 내용은 Object Storage 콘솔 사용 가이드를 참고하십시오.
- 리전은 Object Storage 가이드의 리전별 S3 리전을 참고하십시오.
- 버킷 이름
- 시스템에서 기본 테이블 정보나 관리 테이블 정보, 데이터를 저장하기 위해 사용하는 Object Storage 컨테이너명(dataquery-warehouse)입니다.
- 자체적으로 dataquery-warehouse 컨테이너를 생성해 사용합니다.
- 연동할 기존 데이터들은 dataquery-warehouse 컨테이너 외부에 존재할 수 있습니다.
- 시스템에서 기본 테이블 정보나 관리 테이블 정보, 데이터를 저장하기 위해 사용하는 Object Storage 컨테이너명(dataquery-warehouse)입니다.
- 데이터 소스 이름
- 그 외 사항
- 연동할 Object Storage는 같은 NHN Cloud 프로젝트 외부에 존재할 수 있습니다.
[주의] DataQuery와 연동할 Object Storage가 서로 동일한 리전이 아닐 경우 네트워크 트래픽으로 인한 추가 요금이 발생할 수 있습니다.
- 연동할 Object Storage는 같은 NHN Cloud 프로젝트 외부에 존재할 수 있습니다.
MySQL 데이터 소스 유형
- 데이터 소스 이름
- 쿼리 수행 시 사용되는 구분자이며, 데이터 소스 사이에서 고유한 값이어야 합니다.
- 접속 URL
- MySQL 데이터베이스 접속 주소입니다.
- jdbc:mysql://[호스트,ip]:[포트]?[파라미터] 포맷으로 입력해야 합니다.
- 타임존 처리가 필요할 경우 serverTimezone 파라미터를 설정해야 합니다.
- ex) jdbc:mysql://localhost:10000?serverTimezone=Asia/Seoul
- 사용자 ID
- 접속할 MySQL 계정명입니다.
- 비밀번호
- 접속할 MySQL 비밀번호입니다.
PostgreSQL 데이터 소스 유형
- 데이터 소스 이름
- 쿼리 수행 시 사용되는 구분자이며, 데이터 소스 사이에서 고유한 값이어야 합니다.
- 접속 URL
- PostgreSQL 데이터베이스 접속 주소입니다.
- jdbc:postgresql://[호스트,ip]:[포트]/[데이터베이스]?[파라미터] 포맷으로 입력해야 합니다.
- 사용자 ID
- 접속할 PostgreSQL 계정명입니다.
- 비밀번호
- 접속할 PostgreSQL 비밀번호입니다.
Oracle 데이터 소스 유형
- 데이터 소스 이름
- 쿼리 수행 시 사용되는 구분자이며, 데이터 소스 사이에서 고유한 값이어야 합니다.
- 접속 URL
- Oracle 데이터베이스 접속 주소입니다.
- jdbc:oracle:thin:@[호스트,ip]:[포트]:[SID] 또는 jdbc:oracle:thin:@[호스트,ip]:[포트]/[SERVICE NAME] 포맷으로 입력해야 합니다.
- 사용자 ID
- 접속할 Oracle 계정명입니다.
- 비밀번호
- 접속할 Oracle 비밀번호입니다.
- 추가 설정 정보
- 미지원 타입 처리: 지원하지 않는 열 데이터 타입에 대한 처리 방법을 정할 수 있습니다.
- 기본 소수부 자릿수: 전체 유효 자릿수(precision), 소수점 이하 자릿수(scale) 설정이 없는 숫자에 대한 기본 소수부 자릿수를 설정합니다.
- 숫자 올림/버림: Oracle NUMBER 데이터 타입에 대한 올림/버림 정책을 설정합니다.
EDB 데이터 소스 유형
- 데이터 소스 이름
- 쿼리 수행 시 사용되는 구분자이며, 데이터 소스 사이에서 고유한 값이어야 합니다.
- 접속 URL
- EDB 데이터베이스 접속 주소입니다.
- jdbc:postgresql://[호스트,ip]:[포트]?[파라미터] 포맷으로 입력해야 합니다.
- 사용자 ID
- 접속할 EDB 계정명입니다.
- 비밀번호
- 접속할 EDB 비밀번호입니다.
쿼리 편집기
- 쿼리 편집기는 클러스터 영역, 스키마 영역, 저장된 쿼리 영역, 편집기 영역, 결과/콘솔 실행 영역으로 구분됩니다.
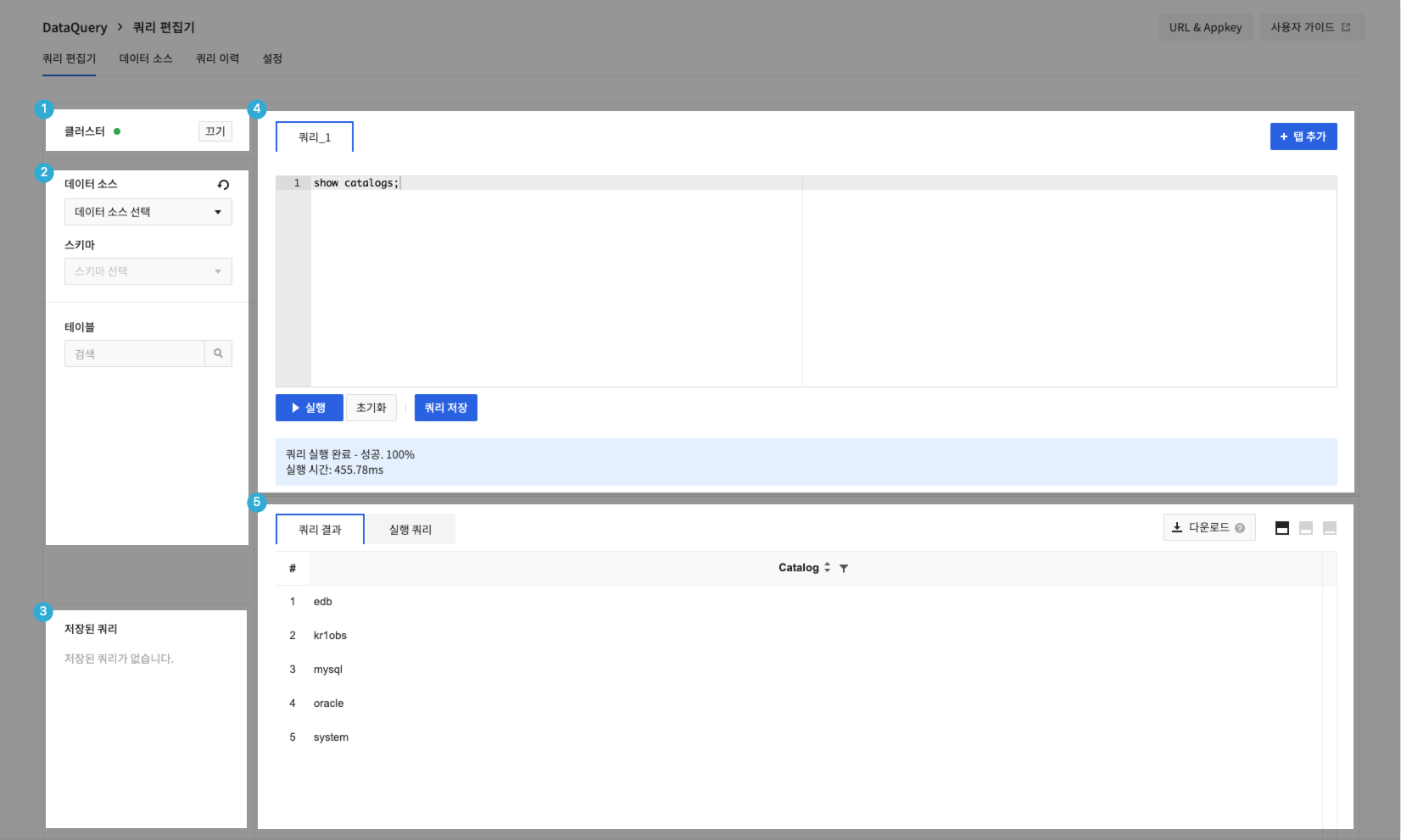
1. 클러스터 영역
- 클러스터를 켜거나 끌 수 있습니다.
- 추가, 변경, 삭제한 데이터 소스 정보가 실제 동작에 반영되려면 DataQuery 클러스터를 다시 시작해야 합니다.
- 데이터 소스를 추가했거나 변경, 삭제 등의 동작이 있었을 경우 아래와 같이 클러스터 재시작 문구가 나타납니다.
- Object Storage는 필수 데이터 소스로, Object Storage 데이터 소스가 삭제되면 클러스터 시작이 불가능합니다.
- 클러스터를 끄는 데 1~2분, 켜는 데 3~4분 정도의 시간이 소요될 수 있습니다.
- DataQuery 클러스터는 모든 데이터 소스를 반영하며, 개별적인 데이터 소스 적용은 불가능합니다.
- 지속적으로 클러스터 켜기 또는 끄기에 실패할 경우, 고객 센터로 문의하십시오.
2. 스키마 영역
- 연결 설정된 데이터 소스와 해당 소스에서 제공하는 실제 DB , 테이블, 칼럼 정보를 확인할 수 있습니다.
- information_schema는 데이터 소스와의 연결 정보를 가지고 있는 DB로 사용자가 임의로 데이터를 조작할 수 없습니다.
- 각 항목의 새로 고침 아이콘을 클릭해 데이터 소스, 스키마, 테이블, 칼럼 정보를 새롭게 가져올 수 있습니다.
- 단, 상위 스키마를 새로 고침하더라도 하위 정보는 새로 불러오지 않습니다. 테이블을 새로 고침할 경우 테이블 목록만 새로 가져오고 각 테이블의 칼럼 정보는 업데이트되지 않습니다.
3. 저장된 쿼리 영역
- 사용자가 저장한 쿼리를 관리할 수 있습니다.
- 열기를 클릭해 현재 열려 있는 쿼리 편집기 영역에 저장한 쿼리를 불러올 수 있습니다.
- 새 탭 열기를 클릭해 새로운 쿼리 편집기 영역에 저장된 쿼리를 불러올 수 있습니다.
- 쿼리 복사를 클릭해 클립보드에 저장된 쿼리를 복사할 수 있습니다.
4. 편집기 영역
- + 쿼리 추가를 클릭해 쿼리 편집기를 최대 10개까지 생성할 수 있습니다.
- 실행을 클릭하거나 ctrl + enter를 입력하여 쿼리를 실행할 수 있으며, 편집기 하단에서 실행 중인 쿼리의 진행 상태와 실패 시 원인 로그를 확인할 수 있습니다.
- 쿼리 저장을 클릭해 사용자가 자주 사용하는 쿼리를 저장할 수 있습니다.
- 쿼리 작성 시 수집된 데이터 소스, 스키마, 테이블, 칼럼명에 대한 자동 완성을 지원합니다.
SQL 가이드
- DataQuery의 SQL은 Trino 기준에 따라 동작합니다.
- Trino는 표준 SQL 문법(ANSI SQL)을 따릅니다.
- Trino는 자체적으로 데이터를 가지지 않으며, 여러 데이터 소스들과의 연동을 통해 데이터를 처리합니다.
- 데이터 소스별로 예외적인 문법이나 제약 사항이 존재할 수 있습니다.
- 트랜잭션 처리(OLTP) 작업이 아닌 분석 처리(OLAP) 작업에 맞춰 설계되었습니다.
- 데이터 타입
- BOOLEAN, 정수형, 소수점, 문자열, 날짜, UUID, 하이퍼로그 등의 타입을 지원합니다.
- Trino 쿼리
- DDL(Data Definition Language, 데이터 정의어), DML(Data Manipulation Language, 데이터 조작어)을 지원하며 아래와 같은 추가 구문을 지원합니다.
- 메타데이터를 확인할 수 있는 구문: SHOW CATALOGS, SHOW SCHEMAS, SHOW TABLES, SHOW STATS FOR
- 시스템의 내장 프로시저(Procedure)를 확인하거나 쿼리의 실행 계획을 확인할 수 있는 구문: CALL, EXPLAIN
- DDL(Data Definition Language, 데이터 정의어), DML(Data Manipulation Language, 데이터 조작어)을 지원하며 아래와 같은 추가 구문을 지원합니다.
- 자세한 사항은 Trino의 가이드 문서를 참고하십시오.
5. 결과/콘솔 실행 쿼리 영역
- 쿼리 편집기에서 실행된 쿼리 결과를 확인할 수 있습니다.
- 데이터 크기에 따라 약 1MB 또는 약 5,000개 정도의 제한된 결과를 제공합니다.
- 쿼리 결과는 최대 30MB까지 다운로드할 수 있습니다.
- Trino를 직접 연동(ex. JDBC, CLI)하면 쿼리 수행 결과 전체에 대한 데이터를 얻을 수 있습니다. 설정 메뉴 가이드를 참고하십시오.
- 쿼리 결과는 쿼리 완료 시각으로부터 최대 7일까지 다운로드할 수 있습니다. 12월 1일 13시 53분 32초에 쿼리 실행이 완료될 경우 12월 8일 13시 53분 32초 전까지 다운로드할 수 있습니다.
- 마우스 오른쪽 버튼을 클릭하여 콘솔 쿼리 결과 복사, 내보내기를 실행할 수 있습니다.
- 쿼리 편집기에서 실행한 쿼리 목록을 제공합니다.
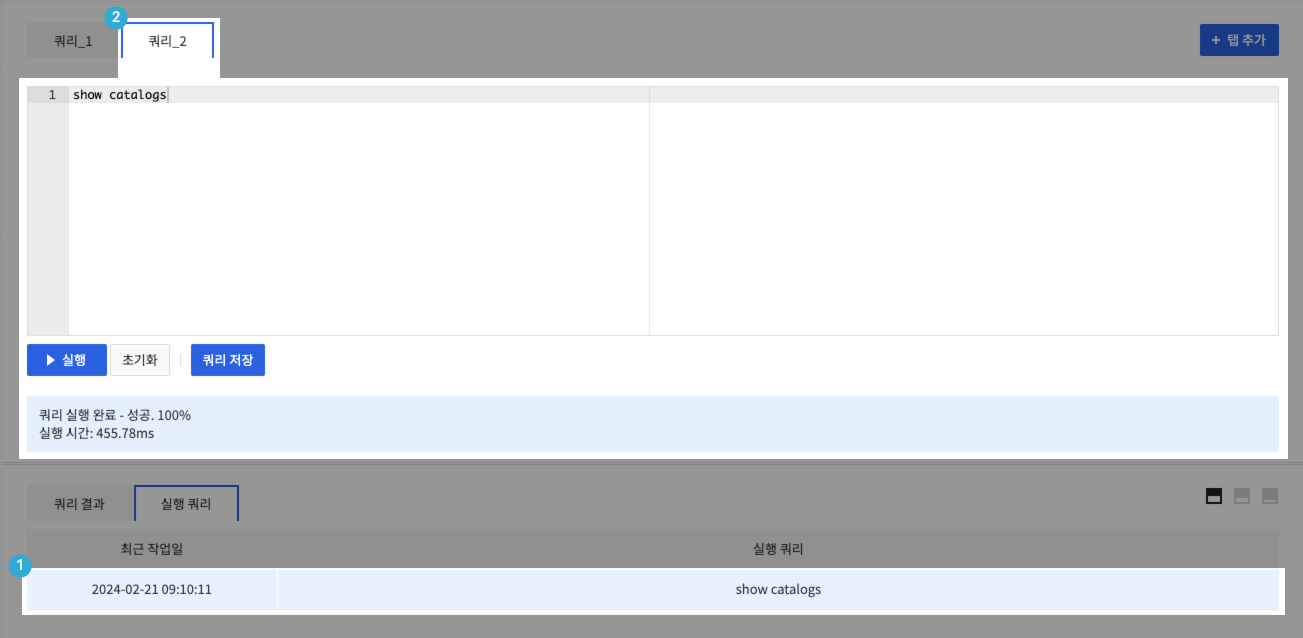
- ① 쿼리 이력을 클릭합니다.
- ② 해당 쿼리가 입력된 쿼리 창이 추가 생성됩니다.
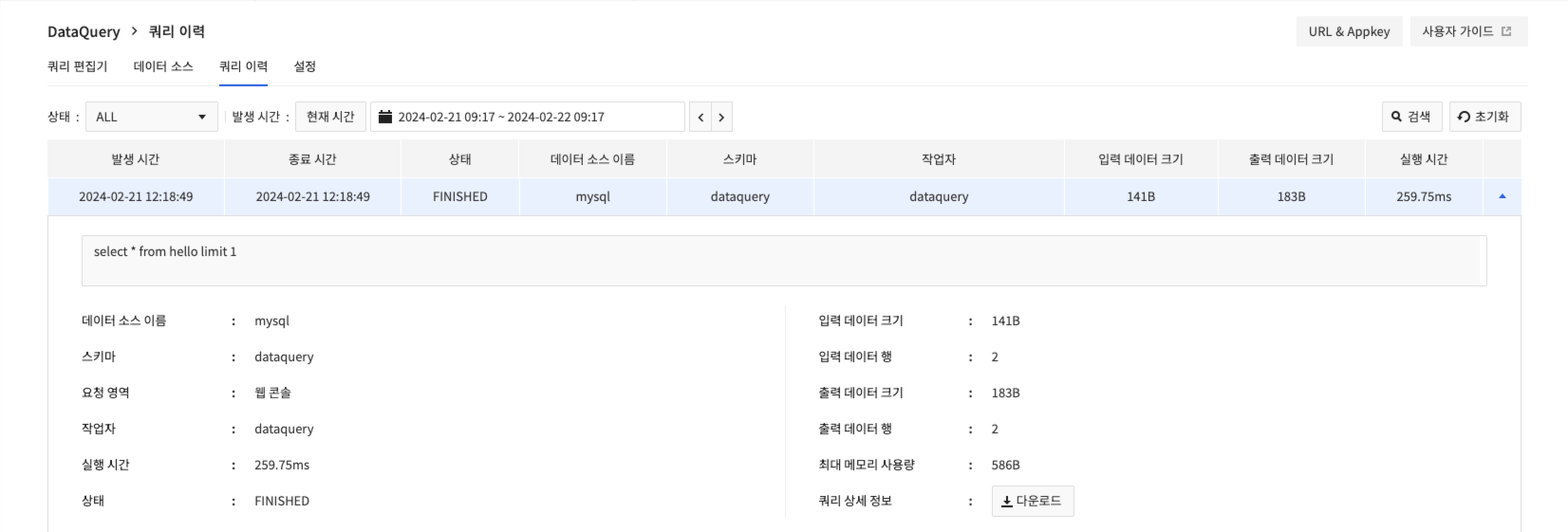
쿼리 이력
- 실행한 쿼리 정보를 쿼리 이력 화면에서 확인할 수 있습니다.
- 가장 오른쪽 열의 펼침 버튼을 클릭해 쿼리의 추가적인 실행 정보를 확인할 수 있으며, 다운로드를 클릭해 쿼리의 전체 실행 정보를 내려받을 수 있습니다.
- 다운로드 파일에 쿼리 결과는 포함되지 않습니다.
설정
클러스터 설정
- 클러스터에 설정된 인스턴스 유형과 노드 수를 확인할 수 있습니다.
- 유형에 대한 설명이나 설정에서 제공되는 목록 이외의 유형은 서비스별 요금에서 확인할 수 있습니다.
- 인스턴스 유형과 워커 수를 변경할 수 있습니다.
- 워커 수는 최소 1개에서 최대 5개까지 설정할 수 있습니다.
- 설정은 클러스터가 꺼진 상태(OFF)에서만 수정이 가능합니다.
외부 연동
- 외부 툴(JDBC, CLI, BI 솔루션 등)과 연동할 수 있도록 Trino 엔드포인트를 제공하며 설정 페이지에서 제공하는 정보를 이용하여 연동할 수 있습니다.
- 엔드포인트 접속을 위해서는 개인별 인증 정보가 필요하며, 설정 메뉴에서 인증 키 발급을 클릭해 발급 받을 수 있습니다.
- 개인별 인증 정보는 ID와 인증 키로 구성되어 있으며 엔드포인트에 접속할 때 사용자 이름(ID)과 비밀번호(인증 키)로 활용됩니다.
- 비밀번호(인증 키)는 최초 발급 시에만 확인할 수 있습니다. 인증 키를 분실할 경우 인증 키 재발급을 클릭해 새 인증 키를 발급 받아야 합니다.
- 발급/재발급된 인증 키는 발급하고 5분이 지난 뒤부터 사용할 수 있습니다.
- 인증 정보가 발급되었다면 Trino 엔드포인트 접속 정보가 화면 하단에 활성화됩니다.
데이터 소스 상세 가이드
Object Storage 데이터 소스 쿼리 실행
- Object Storage 데이터 소스에 대한 쿼리는 Trino-Hive를 기반으로 수행됩니다.
- Hive는 Apache Hadoop 분산 스토리지 환경에서 SQL 작업 처리를 지원하기 위한 솔루션입니다.
- DataQuery에서는 Object Storage 접근을 위해 S3 호환 레이어를 사용하며, 스키마 또는 테이블을 위한 데이터 경로 지정 시 s3a 프로토콜을 사용해야 합니다(ex. s3a://example/test).
- Object Storage 상의 Parquet, JSON, ORC, CSV, Text 타입의 데이터에 대한 처리를 지원합니다.
- Object Storage 데이터 소스는 default라는 이름의 기본 스키마를 제공하며, 해당 스키마에서 작업할 수 있습니다.
Hive 기능 동작을 위한 부가적인 문법
- Trino-Hive는 기본적으로 표준 SQL 문법을 따르지만 Hive 동작 대응을 위한 부가적인 기능/문법이 존재합니다. 상세 정보
- 지원 데이터 포맷
- 기본 포맷은 ORC로 지정되어 있으며, 설정으로 Parquet, JSON, ORC, CSV, Text 등을 지정할 수 있습니다.
- 테이블 생성 시 with절의 format 값으로 지정할 수 있습니다.
CREATE TABLE sample (...) WITH ( format = '타입')
- 테이블 종류
- 내부 테이블(Managed Table)
- DB 생성 시에 지정된 특정 경로에서(dataquery-warehouse 버킷) 테이블 데이터가 관리됩니다.
- 테이블을 삭제하면 테이블 정보 및 Object Storage에 저장된 파일도 함께 삭제됩니다.
- 테이블을 생성할 때 별도의 옵션을 지정하지 않으면 내부 테이블로 생성됩니다.
- 외부 테이블(External Table)
- 사용자가 지정한 별도의 경로에 위치한 데이터를 기반으로 동작합니다.
- 테이블을 삭제할 때 내부 테이블과는 달리 연결된 데이터 원본은 삭제되지 않습니다.
- 테이블을 생성할 때 WITH절의 external_location에 데이터의 경로를 지정해야 합니다.
- external_location 데이터의 경로 입력 시 버킷(컨테이너)명은 NHN Cloud Object Storage의 버킷 명명 규칙을 지켜야 합니다.
- 내부 테이블(Managed Table)
# Managed Table 샘플
CREATE TABLE sample (...);
# External Table 샘플
CREATE TABLE sample (...) WITH ( external_location = 's3a://<버킷,컨테이너명>/<데이터 디렉토리 경로>/');
- 파티션(Partition)
- Hive는 데이터를 특정 기준의 디렉터리로 분리하여 저장할 수 있는 파티션 기능을 제공합니다.
- 테이블에 파티션을 적용하거나 파티션을 조작하려면 아래와 같은 쿼리가 필요합니다.
#테이블에 파티션을 적용하여 생성
CREATE TABLE default.sample (...) WITH ( partitioned_by = ARRAY['columna', 'columnb'],)
#파티션 조회
SELECT * FROM default"sample$partitions"
#파티션을 조작
system.create_empty_partition(schema_name, table_name, partition_columns, partition_values)
system.sync_partition_metadata(schema_name, table_name, mode, case_sensitive)
- 제약 사항
- CSV 타입의 테이블 칼럼은 VARCHAR 타입만 지원됩니다.
- DataQuery에서는 Object Storage 접근을 위해 S3 호환 레이어를 사용하며, 스키마 또는 테이블을 위한 데이터 경로 지정 시 s3a 프로토콜을 사용해야 합니다(ex. s3a://example/test).
- External table의 external_location로 지정되는 데이터 디렉터리 경로 객체가 별도로 존재해야 합니다.
- Object Storage에서 디렉터리를 별도로 생성한 상태에서 데이터가 해당 디렉토리에 위치해야 정상적으로 연동이 될 수 있습니다.
- 만약 해당 처리에 문제가 있을 경우에는 고객 센터로 문의하십시오.
- External table의 external_location 경로명에 한글이 들어갈 경우 정상적으로 데이터가 처리되지 않습니다.
- 테이블과 연결된 Object Storage 버킷이 삭제되면 테이블 DROP 쿼리가 실패합니다.
- DELETE, UPDATE는 파티션 데이터에 대해서만 제한적으로 수행할 수 있습니다.
외부 테이블 쿼리 이용 튜토리얼
- 샘플 CSV 파일을 다운로드하여 Object Storage에 업로드합니다.
- Object Storage 콘솔에서 액세스 키, 시크릿 키를 발급 받습니다.
- Object Storage의 액세스 키, 시크릿 키, 엔드포인트를 이용하여 Object Storage 데이터 소스를 입력합니다.
- 쿼리 편집기로 이동하여 방금 전 추가한 Object Storage 데이터 소스를 선택하고 default 스키마를 선택합니다.
- 아래와 같이 CREATE TABLE 쿼리문을 입력하여 실행합니다.
CREATE TABLE corona_facility_us
(
facility_place_id varchar,
facility_provider_id varchar,
facility_name varchar,
facility_latitude varchar,
facility_longitude varchar,
facility_country_region varchar,
facility_country_region_code varchar,
facility_sub_region_1 varchar,
facility_sub_region_1_code varchar,
facility_sub_region_2 varchar,
facility_sub_region_2_code varchar,
facility_region_place_id varchar,
mode_of_transportation varchar,
travel_time_threshold_minutes varchar,
facility_catchment_boundary varchar
)
with (
format = 'csv',
external_location = 's3a://csv-test/corona-facility/'
)
- 테이블이 정상적으로 추가되었는지 확인하기 위해 테이블을 새로 고침합니다.
- 해당 테이블에서 아래와 같이 쿼리를 실행합니다.
SELECT * FROM corona_facility_us
WHERE facility_place_id = 'ChIJkxHDPsnTQIYR7MH7N-eIdQ0'
AND facility_latitude = '29.952'
- 총 10건의 데이터가 정상적으로 나오는지 확인합니다.
MySQL 데이터 소스 쿼리 실행
- MySQL 데이터 소스에 대한 쿼리는 Trino-MySQL을 기반으로 수행됩니다.
- MySQL 데이터 소스의 스키마와 테이블은 소문자명을 기반으로 동작하고 표현됩니다.
- 대소문자가 다른 같은 이름의 테이블이 있으면 쿼리 실행 및 스키마 수집이 정상 동작하지 않을 수 있습니다.
- 제약 사항
- DELETE는 특정 조건이 충족될 때만 제한적으로 수행할 수 있습니다.
- where 절이 존재할 때 조건자(Predicate)가 데이터 소스로 온전히 푸시다운(Pushdown)될 수 있어야 합니다.
- 텍스트 타입의 열은 푸시다운이 지원되지 않습니다.
- 상세 정보
- UPDATE는 특정 조건이 충족될 때만 제한적으로 수행할 수 있습니다.
- 상수 값으로의 할당 및 조건자(Predicate)가 존재할 경우에만 수행할 수 있습니다.
- 산술 표현식, 함수 호출 및 상수가 아닌 값으로의 UPDATE문은 지원되지 않습니다.
- 조건 절을 AND로 구성할 수 없습니다.
- 테이블의 모든 열을 동시에 업데이트할 수 없습니다.
- 상세 정보
- DELETE는 특정 조건이 충족될 때만 제한적으로 수행할 수 있습니다.
PostgreSQL 데이터 소스 쿼리 실행
- PostgreSQL 데이터 소스에 대한 쿼리는 Trino-PostgreSQL을 기반으로 수행됩니다.
- PostgreSQL 데이터 소스의 스키마와 테이블은 소문자명을 기반으로 동작하고 표현됩니다.
- 대소문자가 다른 같은 이름의 테이블이 있으면 쿼리 실행 및 스키마 수집이 정상 동작하지 않을 수 있습니다.
- 제약 사항
- DELETE는 특정 조건이 충족될 때만 제한적으로 수행할 수 있습니다.
- where 절이 존재할 때 조건자(Predicate)가 데이터 소스로 온전히 푸시다운(Pushdown)될 수 있어야 합니다.
- CHAR 또는 VARCHAR와 같은 문자열 유형에 대한 범위 조건(>, < 또는 BETWEEN)은 푸시다운이 지원되지 않습니다.
- 텍스트 타입에 대한 동등 비교 조건(IN, =, !=)은 푸시다운이 지원됩니다.
- 상세 정보
- UPDATE는 특정 조건이 충족될 때만 제한적으로 수행할 수 있습니다.
- 상수 값으로의 할당 및 조건자(Predicate)가 존재할 경우에만 수행할 수 있습니다.
- 산술 표현식, 함수 호출 및 상수가 아닌 값으로의 UPDATE문은 지원되지 않습니다.
- 조건 절을 AND로 구성할 수 없습니다.
- 테이블의 모든 열을 동시에 업데이트할 수 없습니다.
- 상세 정보
- DELETE는 특정 조건이 충족될 때만 제한적으로 수행할 수 있습니다.
Oracle 데이터 소스 쿼리 실행
- Oracle 데이터 소스에 대한 쿼리는 Trino-Oracle을 기반으로 수행됩니다.
- Oracle 데이터 소스의 스키마와 테이블은 소문자명을 기반으로 동작하고 표현됩니다.
- 대소문자가 다른 같은 이름의 테이블이 있으면 쿼리 실행 및 스키마 수집이 정상 동작하지 않을 수 있습니다.
- 제약 사항
- DELETE, UPDATE는 특정 조건이 충족될 때만 제한적으로 수행할 수 있습니다.
- where 절이 존재할 때 조건자(Predicate)가 데이터 소스로 온전히 푸시다운(Pushdown)될 수 있어야 합니다.
- CLOB, NCLOB, BLOB, or RAW(n)인 Oracle 타입의 열은 푸시다운이 지원되지 않습니다.
- 상세 정보
- UPDATE는 특정 조건이 충족될 때만 제한적으로 수행할 수 있습니다.
- 상수 값으로의 할당 및 조건자(Predicate)가 존재할 경우에만 수행할 수 있습니다.
- 산술 표현식, 함수 호출 및 상수가 아닌 값으로의 UPDATE문은 지원되지 않습니다.
- 조건 절을 AND로 구성할 수 없습니다.
- 테이블의 모든 열을 동시에 업데이트할 수 없습니다.
- 상세 정보
- DELETE, UPDATE는 특정 조건이 충족될 때만 제한적으로 수행할 수 있습니다.
EDB 데이터 소스 쿼리 실행
- EDB 데이터 소스에 대한 쿼리는 Trino-PostgreSQL을 기반으로 수행됩니다.
- EDB 데이터 소스의 스키마와 테이블은 소문자명을 기반으로 동작하고 표현됩니다.
- 대소문자가 다른 같은 이름의 테이블이 있으면 쿼리 실행 및 스키마 수집이 정상 동작하지 않을 수 있습니다.
- 제약 사항
- DELETE는 특정 조건이 충족될 때만 제한적으로 수행할 수 있습니다.
- where 절이 존재할 때 조건자(Predicate)가 데이터 소스로 온전히 푸시다운(Pushdown)될 수 있어야 합니다.
- CHAR 또는 VARCHAR와 같은 문자열 유형에 대한 범위 조건(>, < 또는 BETWEEN)은 푸시다운이 지원되지 않습니다.
- 텍스트 타입에 대한 동등 비교 조건(IN, =, !=)은 푸시다운이 지원됩니다.
- 상세 정보
- UPDATE는 특정 조건이 충족될 때만 제한적으로 수행할 수 있습니다.
- 상수 값으로의 할당 및 조건자(Predicate)가 존재할 경우에만 수행할 수 있습니다.
- 산술 표현식, 함수 호출 및 상수가 아닌 값으로의 UPDATE문은 지원되지 않습니다.
- 조건 절을 AND로 구성할 수 없습니다.
- 테이블의 모든 열을 동시에 업데이트할 수 없습니다.
- 상세 정보
- DELETE는 특정 조건이 충족될 때만 제한적으로 수행할 수 있습니다.
외부 연동
Trino cli
- 설정 메뉴를 통해 발급 받은 인증 정보, 접속 정보와 Trino에서 지원하는 CLI 툴을 통해 커맨드라인에서 쿼리를 실행할 수 있습니다.
- Trino에서 지원하는 CLI 툴은 최신 버전을 사용하십시오.
- 현재 DataQuery에서 제공하고 있는 Trino 버전은 434입니다.
- Trino CLI
# 파일에 실행 권한이 필요합니다. chmod +x로 부여할 수 있습니다.
# ex) chmod +x trino-cli-434-executable.jar
./trino-cli-434-executable.jar --server <접속URL(필수)> \
--user <아이디(필수)> --password \
--catalog <데이터 소스 이름> \
--schema <스키마 이름>
- 설정 파라미터
- 접속 URL(필수)
- 설정 화면에서 제공 받은 접속 URL (ex. https://x-x-x-x-x.kr1-cluster-dataquery.nhncloudservice.com)
- 아이디(필수)
- 인증 정보 화면에서 제공 받은 아이디
- 비밀번호(필수)
- 인증 정보 화면에서 제공 받은 비밀번호
- 커맨드를 실행하면 나오는 프롬프트 창에서 입력하거나
export TRINO_PASSWORD=<비밀번호>로 비밀번호를 미리 설정할 수 있습니다.
- 데이터 소스 이름
- 연결한 데이터 소스 이름
- 스키마 이름
- 연결한 스키마 이름
- 접속 URL(필수)
--debug옵션을 추가하여 디버그 정보를 추가로 출력할 수 있습니다.- catalog, schema 값은 명령을 수행할 연결에 대한 값으로, 입력하지 않아도 cli를 실행할 수 있으며 아래 쿼리를 이용해 catalog나 schema 목록을 확인할 수 있습니다.
- show catalogs
- show schemas
- 더 자세한 정보는 Trino 가이드 페이지를 참고하십시오.
JDBC 연결
- 설정 메뉴에서 발급 받은 인증 정보, 접속 정보와 Trino에서 지원하는 JDBC 드라이버를 이용해 JDBC에 연결할 수 있습니다.
jdbc:trino://${host}:${port}
jdbc:trino://${host}:${port}/${catalog}
jdbc:trino://${host}:${port}/${catalog}/${schema}
- 설정 파라미터
- host(필수)
- 설정 화면에서 제공 받은 접속 URL에서
https://를 제외한 나머지를 입력합니다(ex . x-x-x-x-x.kr1-cluster-dataquery.nhncloudservice.com).
- 설정 화면에서 제공 받은 접속 URL에서
- port(필수)
- 443을 입력합니다.
- catalog
- 연결을 원하는 데이터 소스 이름
- schema
- 연결을 원하는 스키마 이름
- host(필수)
- 접속 정보 예시
- jdbc:trino://test-dataquery-domain-12345abcd.kr1-cluster-dataquery.nhncloudservice.com:443/catalog/schema
- 더 자세한 정보는 Trino JDBC 가이드 페이지를 참고하십시오.
목차
- Data & Analytics > DataQuery > 콘솔 사용 가이드
- 데이터 소스
- 데이터 소스 추가
- Object Storage 데이터 소스 유형
- MySQL 데이터 소스 유형
- PostgreSQL 데이터 소스 유형
- Oracle 데이터 소스 유형
- EDB 데이터 소스 유형
- 쿼리 편집기
- 1. 클러스터 영역
- 2. 스키마 영역
- 3. 저장된 쿼리 영역
- 4. 편집기 영역
- 5. 결과/콘솔 실행 쿼리 영역
- 쿼리 이력
- 설정
- 클러스터 설정
- 외부 연동
- 데이터 소스 상세 가이드
- Object Storage 데이터 소스 쿼리 실행
- MySQL 데이터 소스 쿼리 실행
- PostgreSQL 데이터 소스 쿼리 실행
- Oracle 데이터 소스 쿼리 실행
- EDB 데이터 소스 쿼리 실행
- 외부 연동
- Trino cli
- JDBC 연결